- Introduction
- 1. Introduction to Quantitative Analysis
- 2. Descriptive Statistics
- 3. T-test for Difference in Means and Hypothesis Testing
- 4. Bivariate linear regression models
- 5. Multiple linear regression models
- 6. Assumptions and Violations of Assumptions
- 7. Interactions
- 8. Panel Data, Time-Series Cross-Section Models
- 9. Binary models: Logit
- 10. Frequently Asked Questions
- 11. Optional Material
- 12. Datasets
- 13. R Resources
- 14. References
- Published with GitBook
5. Multiple linear regression models
5.2 Solutions
library(Zelig) # to predict from regression output and present uncertainty
library(texreg) # to plot regression output to screen or file
Warning: package 'texreg' was built under R version 3.2.3
Exercise 1
Clear your workspace and set your working directory to "N:/PUBLG100" if you work on a UCL computer or to your preferred computer if you work on your own computer.
Solution
# clear workspace
rm(list = ls() )
# set working directory
setwd("N:/PUBLG100")
Exercise 2
Load the data set corruption.csv http://uclspp.github.io/PUBLG100/data/corruption.csv. Hint: the read.csv() function is needed for this.
Solution
# load csv data set
cor.data <- read.csv("http://uclspp.github.io/PUBLG100/data/corruption.csv")
Exercise 3
Inspect the data. Spending some time here will help you for the next tasks. Knowing and understanding your data will help you when running and interpreting models and you are less prone to making mistakes.
Solution
There are many different ways to get an overview over the data. The important thing is that you know the levels of measurement and that you are roughly familiar with the range of the variables.
summary(cor.data)
country country.code country.abbr ti.cpi
Albania : 1 Min. : 8.0 AGO : 1 Min. :1.200
Algeria : 1 1st Qu.:209.0 ALB : 1 1st Qu.:2.500
Angola : 1 Median :420.0 ARE : 1 Median :3.300
Argentina: 1 Mean :431.5 ARG : 1 Mean :4.051
Armenia : 1 3rd Qu.:658.0 ARM : 1 3rd Qu.:4.900
Australia: 1 Max. :894.0 AUS : 1 Max. :9.700
(Other) :164 (Other):164
gdp region
Min. : 520 Africa :51
1st Qu.: 1974 Americas:32
Median : 5280 Asia :48
Mean : 8950 Europe :39
3rd Qu.:10862
Max. :61190
Exercise 4
Run a regression on gdp. Use ti.cpi (corruption perceptions index, larger values mean less corruption) and region as independent variables. Print the model results to a world file called "model1.doc". Also print, your output to the screen.
Region is a categorical variable and R recognizes it as a factor variable. The variable has four categories corresponding to the four regions. When you run the model, the regions are included as binary variables (also sometimes called dummies) that take the values 0 or 1. For example, regionAmericas is 1 when the observation (the country) is from the Americas. Only three regions are included in the model, while the fourth is what we call the baseline or reference category. It is included in the intercept. Interpreting the intercept would mean, looking at an African country when ti.cpi is zero. If the estimate for the region dummy Europe is significant then that means that there is a difference in the dependent variable between European countries and the baseline category Africa.
Solution
# estimate linear multivariate regression model
m1 <- lm(gdp ~ ti.cpi + region, data = cor.data)
# print model output to word file
htmlreg(m1, file = "model1.doc")
The table was written to the file 'model1.doc'.
# print output to screen
screenreg(m1)
============================
Model 1
----------------------------
(Intercept) -6607.83 ***
(992.80)
ti.cpi 3437.55 ***
(221.40)
regionAmericas 104.63
(1243.02)
regionAsia 1036.41
(1103.24)
regionEurope 5758.61 ***
(1287.72)
----------------------------
R^2 0.72
Adj. R^2 0.71
Num. obs. 170
RMSE 5375.97
============================
*** p < 0.001, ** p < 0.01, * p < 0.05
Exercise 5
Does the inclusion of region improve model fit compared to a model without regions but with the corruption perceptions index? Hint: You need to compare two models.
Solution
To do this, we estimate a model with ti.cpi but without the regions. We then run an F-test comparing the the two models. Taking a look at the p-value reveals we can reject the null hypothesis that the reduction in the unexplained error is due to chance. Our model including regions is an improvement over the more general model.
# estimate linear model excluding regions
m.noregions <- lm(gdp ~ ti.cpi, data = cor.data)
# joint hypothesis testing
anova(m.noregions, m1)
Analysis of Variance Table
Model 1: gdp ~ ti.cpi
Model 2: gdp ~ ti.cpi + region
Res.Df RSS Df Sum of Sq F Pr(>F)
1 168 5504948435
2 165 4768671746 3 736276689 8.4919 2.802e-05 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Exercise 6
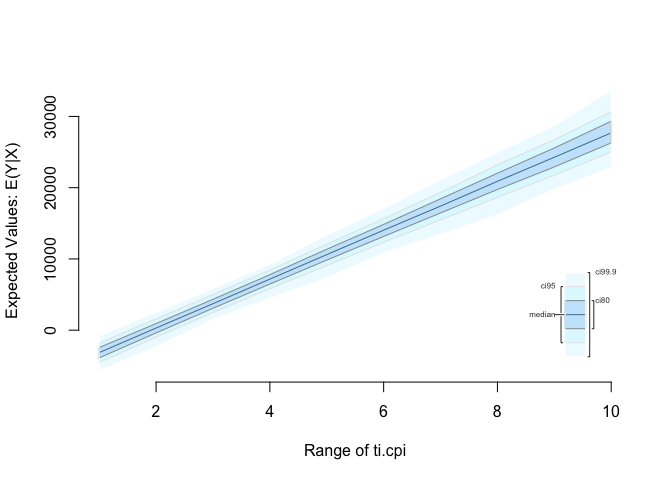
Predict gdp by varying ti_cpi from lowest to highest using the model that includes region. Plot your results.
Solution
We do this using zelig(). First, we estimate a linear model. Then we check the range of ti.cpi which varies roughly from 1 to 10. Then we set our covariates. And vary ti.cpi from 1 to 10. Next, we simulate using our model and the covariates and finally plot our predictions.
# estimate the linar model including regions
linear.model <- zelig( gdp ~ ti.cpi + region, data = cor.data, model = "ls")
How to cite this model in Zelig:
Kosuke Imai, Gary King, and Olivia Lau. 2015.
"ls: Least Squares Regression for Continuous Dependent Variables"
in Kosuke Imai, Gary King, and Olivia Lau, "Zelig: Everyone's Statistical Software,"
http://gking.harvard.edu/zelig
# look at the ti.cpi variable to see the range
summary( cor.data$ti.cpi)
Min. 1st Qu. Median Mean 3rd Qu. Max.
1.200 2.500 3.300 4.051 4.900 9.700
# set the covariates
covariates <- setx( linear.model, ti.cpi = 1:10)
# simulate
predictions <- sim( linear.model, covariates)
# plot results
plot(predictions)
Exercise 7
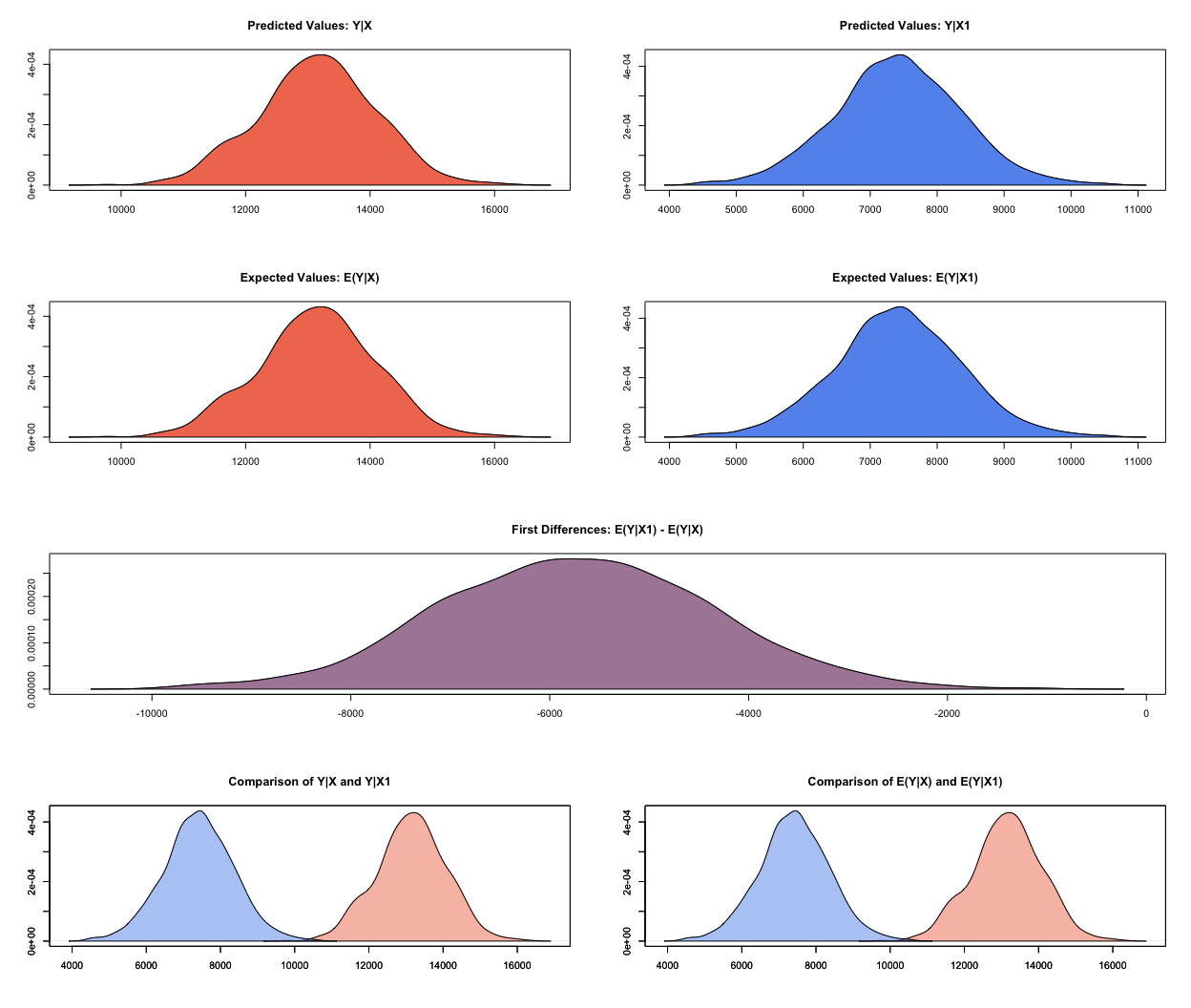
Is there a difference between Europe and the Americas? Hint: is the difference between the predicted values for the two groups significantly different from zero?
Solution
We use zelig just like in exercise 6 but this time we set two specific scenarios. The first is Europe, the second is the Americas. Because ti.cpi is interval scaled and we did not specify a value for it, Zelig automatically sets it to the mean. Once we simulated, we look at the first differences and can confirm that the difference in political stability between the two regions is indeed statistically different from zero.
# estimate the linear model including regions
linear.model <- zelig( gdp ~ ti.cpi + region, data = cor.data, model = "ls")
How to cite this model in Zelig:
Kosuke Imai, Gary King, and Olivia Lau. 2015.
"ls: Least Squares Regression for Continuous Dependent Variables"
in Kosuke Imai, Gary King, and Olivia Lau, "Zelig: Everyone's Statistical Software,"
http://gking.harvard.edu/zelig
# look at the labels of the factor variable regions
table(cor.data$region)
Africa Americas Asia Europe
51 32 48 39
# set the covariates
europa <- setx( linear.model, region = "Europe")
amerika <- setx( linear.model, region = "Americas")
# simulate
predictions <- sim( linear.model, x = europa, x1 = amerika)
# look at the first difference
summary(predictions)
Model: ls
Number of simulations: 1000
Values of X
(Intercept) ti.cpi regionAmericas regionAsia regionEurope
1 1 4.050588 0 0 1
attr(,"assign")
[1] 0 1 2 2 2
attr(,"contrasts")
attr(,"contrasts")$region
[1] "contr.treatment"
Values of X1
(Intercept) ti.cpi regionAmericas regionAsia regionEurope
1 1 4.050588 1 0 0
attr(,"assign")
[1] 0 1 2 2 2
attr(,"contrasts")
attr(,"contrasts")$region
[1] "contr.treatment"
Expected Values: E(Y|X)
mean sd 50% 2.5% 97.5%
1 13143.88 948.09 13148.46 11324.66 14897.34
Expected Values: E(Y|X1)
mean sd 50% 2.5% 97.5%
1 7411.753 952.028 7420.453 5523.18 9313.419
Predicted Values: Y|X
mean sd 50% 2.5% 97.5%
1 13143.88 948.09 13148.46 11324.66 14897.34
Predicted Values: Y|X1
mean sd 50% 2.5% 97.5%
1 7411.753 952.028 7420.453 5523.18 9313.419
First Differences: E(Y|X1) - E(Y|X)
mean sd 50% 2.5% 97.5%
1 -5732.129 1360.073 -5742.004 -8405.733 -3020.748
# you can do this visually, too
plot(predictions)