Performing experiments using FTFs
Predicting one grammatical variable with another, continued
Examples
1. Two features in the same constituent
Q. Does mood affect transitivity in clauses?
Our first example is achieved by simply completing the table in the basic approach. Using ICECUP and the complete ICE-GB corpus, we perform queries for each combination of mood and transitivity, including where features are absent. (We assume that the features within one clause are independent from the features within another.) Note that the overwhelming majority of clauses are not marked for mood (labelled 0 below), i.e., they are indicative. Clauses whose transitivity is unmarked are in error, or the transitivity cannot be determined, possibly as a result of ellipted material. In this case the clause should be labelled ‘CL(incomp)’.
CL |
DV (transitivity) |
||||||||
IV (mood) |
montr |
ditr |
dim'tr |
cxtr |
trans |
intr |
cop |
0 |
TOTAL |
exclam |
6 |
0 |
0 |
0 |
0 |
2 |
14 |
1 |
23 |
inter |
2,223 |
74 |
17 |
135 |
91 |
1,360 |
1,895 |
89 |
5,884 |
imp |
1,066 |
64 |
25 |
126 |
112 |
700 |
54 |
144 |
2,291 |
subjun |
62 |
2 |
1 |
10 |
3 |
83 |
70 |
1 |
232 |
0 |
58,984 |
1,606 |
203 |
3,826 |
2,392 |
30,522 |
30,096 |
9,093 |
136,722 |
TOTAL |
62,341 |
1,746 |
246 |
4,097 |
2,598 |
32,667 |
32,129 |
9,328 |
145,152 |
Frequencies of all permutations of transitivity and mood features for a clause
We can now investigate, for example, if mood affects the use of monotransitive.
Observed O = {6, 2223, 1066, 62, 58984},
montr
TOTAL/SFchi-square
contribution
scale factor SF = 62341/145152 = 0.429,
expected E = {10, 2527, 984, 100, 58720} (approx.).Chi-square χ² = Σ(E-O)²/E = 4²/10 + 304²/2527 + 82²/984 + 38²/100 + 264²/58720 = 60.631 > crit(4, 0.05) = 9.488.
Since χ² > critical value, the result is significant and the null hypothesis, i.e., that monotransitive does not correlate with variation of mood, is rejected.
The table on the right summarises the observed and expected distributions and the contribution that each pair of values (i.e., (E-O)²/E) makes to the overall χ². Note that although there are many cases of ‘mood = unmarked’ (indicative) , this contributes the least variation (264²/58720 = 1.187). The largest contribution to the chi-square are interrogative and subjunctive.
Similarly, to investigate the effect of mood on the ditransitive:
Observed O = {0, 74, 64, 2, 1606};
Expected E = {0, 71, 27.5, 3, 1644.5}
However, one of the assumptions of the chi-square test is that the expected distribution does not include “low-valued cells”, usually taken to mean frequencies below 5. We must therefore “collapse” numbers of cells together. This is the corollary of the ability to group alternatives (see the problem of incomplete enumeration).
Let us consider grouping the exclamative and subjunctive cases with unmarked. The number of degrees of freedom therefore falls to 2.
Observed O = {74, 64, 1608},
ditr
TOTAL/SFchi-square
contribution
scale factor SF = 1746/145152 = 0.012,
expected E = {71, 27.5, 1647.5} (approx.).Chi-square χ² = 3²/71 + 36.5²/27.5 + 39.5²/1647.5 = 49.519 > crit(2, 0.05) = 5.991.
Since χ² > critical value, the result is significant and the null hypothesis, i.e., that ditransitive does not correlate with variation of mood*, is rejected.
*Note that “variation of mood” now means variation between these three cases: interrogative, imperative and everything else, and the largest variance is for the imperative.
We leave the interaction of mood with other transitivity values as an exercise for the reader.
2. Two features within a structure
Q. Does a phrasal adverb affect the following preposition?
What if we want to look at interactions within a group of related constituents rather than within a single node?
Consider clauses containing two adverbial elements: an adverb phrase followed by a prepositional phrase, expressed by the FTF below left. The example “No I load up [AVP] with fast film [PP]” (S1A-009 #19) is summarised below.
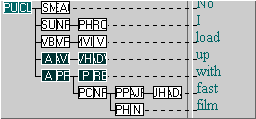
Now suppose that we want to establish if the fact that the adverb in the adverb phrase is or is not phrasal (as in “finding out”, “moving on”, etc.) affects whether the preposition in the following prepositional phrase is also marked as phrasal. We might write something like “ADV(?phras) → PREP(?phras)” as a shorthand (the question mark in our notation indicates that the feature is optional).
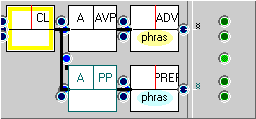
The example below right contrasts with cases such as S1A-006 #60, “It’s only just come out [ADV] in the cinema [PP]” where the preposition “in” is general rather than phrasal.
We therefore introduce two constituents (for the adverb and preposition) into the FTF.
We can construct four FTFs like the one above, identical in all respects except that each has a different combination of features. We then complete the table below using the results of these four searches on ICE-GB (green shading). Note that the IV and DV are both Boolean (the presence or absence of a single feature). If the DV and IV are both true (T) this means that both phrasal features are present (as above). If the DV is true and the IV is false (F), the adverb must not have this feature but the preposition does, and so on.
CL[AVP-ADV PP-PREP] |
dependent
variable (preposition is phrasal ) |
|||
DV
= T PREP(phras) |
DV
= F PREP(¬phras) |
TOTAL |
||
independent
variable |
IV
= T ADV(phras) |
616 |
320 |
936 |
IV
= F ADV(¬phras) |
1,428 |
1,806 |
3,234 |
|
TOTAL |
2,044 |
2,126 |
4,170 |
|
Completing the contingency table for the example above
The analysis for predicting when the preposition is marked as phrasal (DV = T) proceeds as before.
Observed O = {616, 1428},
scale factor SF = 2044/4170 = 0.490,
expected E = {459, 1585} (approx.).Chi-square χ² = 157²/459 + 157²/1585 = 69.253 > crit(1, 0.05) = 3.841.
Since χ² > critical value, the result is significant and the null hypothesis, i.e., that whether a following preposition is marked as phrasal does not correlate with the adverb being phrasal for structures such as this, is rejected.
The presence of the phrasal feature in the preposition (around half the cases in the corpus) becomes two thirds if the adverb contains the phrasal feature. If you wish, you may also perform a second test to check if the absence of the phrasal feature in the preposition also varies significantly with the phrasal feature of the preceding adverb (this is almost certain given its relationship with the first test).
Secondly, we can swap the IV and DV around, i.e., instead of seeing if the presence/absence of the phrasal feature in the adverb affects the likelihood of the presence/absence of the phrasal feature in the following preposition, we could also look at the reverse implication, i.e., “PREP(?phras) → ADV(?phras)”. We should not necessarily limit our investigations to those consistent with word order. The key consideration, as always in designing an experiment, is what theoretical meaning does it have for linguistics?
There may be other variables (e.g., the transitivity of the preceding verb) that also predict when the preposition is phrasal. Such variables may predict the outcome independently, e.g., “V(?trans) → PREP(?phras)” or in conjunction with others, e.g., “V(?trans) and ADV(phras) → PREP(?phras)”.
The problem with examining the interaction of multiple variables is that it can all get very complicated, produce very large tables, and, if you have to perform the process manually, become rather onerous. However, rather than look at all possible interactions (e.g., between the phrasal feature of the adverb and all types of transitivity), there are some simple ways of progressing.
One method is to focus on the most effective predictor value (here, where the adverb is phrasal - hence “ADV(phras)” does not contain a question mark), and use this to specify the FTF that defines your case. You then subdivide these cases by the values of the other variable.
In this case, if the result is significant it means that the transitivity affects the likelihood of phrasal prepositions when the adverb is phrasal. Moreover, certain values of transitivity will improve on the default prediction. (This approach is automated and coupled with a search procedure in a process we call knowledge discovery in corpora.)
Problem: have we effectively captured the aspect of the annotation we require?
There is a certain amount of redundancy in the ICE grammar. In the example above, for instance, the phrasal feature of the adverb is ‘percolated up’ to the adverb phrase. We could, therefore, abstract the variable from the feature in the adverb phrase rather than the adverb. However, this ‘percolation’ is a source of potential error, and so it is best to avoid using such features if at all possible. Likewise, in the next example, we pick up the transitivity from the verb rather than the verb phrase.
NB. In the new ICE-GB R2 and DCPSE corpora, percolation has been applied exhaustively, so this should not be a problem.
3. A feature and a constituent
Q. Does verb transitivity affect the presence of a following adverbial clause?
As well as representing aspects of a node (features, function, category), grammatical variables can represent the presence of a structural item, such as a node, in the first place. In the following example we ask, does the transitivity of a verb predict whether or not the verb phrase might be followed by an adverbial clause?
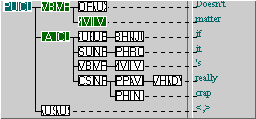
The case is defined simply, by all clauses containing a VP (and a main verb). The presence of a following adverbial clause - as in, “Doesn’t matter if it’s really crap [CL] <,>”, above (S1A-006 #197) - is detected by extending the FTF (below). A white arrow, meaning that the constituent eventually follows the previous one, is employed between the VP and the adverbial clause.
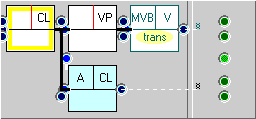
If we want to examine each subclass of transitivity separately (the IV), we must enumerate them in a table and construct FTFs for each one, with and without the adverbial clause. We then fill in the table by looking up the values shaded green, below, and calculating the remainder.
The DV is Boolean (the presence or absence of a constituent).
CL[VP-V(?trans)
?A,CL] |
dependent
variable (adverbial clause) |
|||
DV
= T |
DV
= F |
TOTAL |
||
IV (transitivity of verb) |
intr |
2,766 |
26,848 |
29,614 |
cop |
2,159 |
27,371 |
29,350 |
|
montr |
4,661 |
54,752 |
59,413 |
|
cxtr |
285 |
3,628 |
3,913 |
|
ditr |
118 |
1,574 |
1,692 |
|
dimontr |
19 |
241 |
260 |
|
trans |
130 |
2,401 |
2,531 |
|
0 |
2 |
46 |
48 |
|
TOTAL |
10,140 |
116,681 |
126,821
|
|
Completing the contingency table for the feature → constituent FTF example
The analysis for predicting when the adverbial clause is present (DV = T) proceeds much as before. Since the unmarked (error) transitivity frequency is low (2), we employ the convention that we collapse it into the next lowest cell (IV = dimontr).
Observed O = {2766, 2159, 4661, 285, 118, 21*, 130},
scale factor SF = 10140/126821 = 0.080,
expected E = {2368, 2347, 4750, 313, 135, 25*, 202} (approx.).Chi-square χ² = 398²/2368 + 188²/2347 + 89²/4750 + 28²/313 + 17²/135 + 4²/25 + 72²/202 = 114.578 > crit(5, 0.05) = 11.070.
Since χ² > critical value, the result is significant and the null hypothesis, i.e., that the presence of a following adverbial clause within such clauses does not correlate with the transitivity of the preceding verb, is rejected.
The high chi-square value is due in many cases to the very large number of applicable cases. The largest contribution towards the chi-square is the intransitive case (398²/2368 = 66.894), where the proportion containing an adverbial clause rises from 8% to 9.3%. The next largest contribution is where the transitivity feature is marked transitive (72²/202 = 25.663), the proportion containing an adverbial clause falling to a mere 2.7% (130 out of 2,531).
Problem: what do we do if cases overlap one another?
The example above can fall victim to two different kinds of overlapping.
- The optional adverbial clause is itself the superordinate clause of another case.
- There is more than one VP (this is prevented by the grammar) or adverbial clause within the same superordinate clause.
We can construct an FTF to detect both types of overlap.
- Type 1: Below is an FTF for the first one. We find 8,993 matches in ICE-GB out of 10,140. Nearly 9 out of 10 adverbial clauses in such structures contain a VP and a verb, which is not altogether surprising! Do these clauses interact with one another, and if so, does this undermine the sampling assumptions of the experiment?
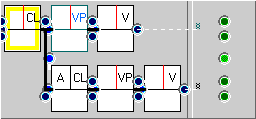
The question is not trivial to answer. In a narrow sense, we are obviously referring to two distinct constituents. However, an adverbial clause which contains another clause is called a complex clause. Moreover, when we examine the results of the query above left, we find that out of the 8,993 cases where the adverbial clause contains a verb, a mere 472 contain a second adverbial clause! The 8% proportion of all cases becomes 4%.
Therefore, it seems that if the clause we are investigating is itself an adverbial within another clause, then it decreases the likelihood that it contains a second adverbial clause. (We can perform a mini-experiment to check this, such that the IV is the presence of the preceding structure and the DV is the presence of the second adverbial clause.)
Type 2: However, this does not tell us how the fact that the clause is an adverbial in another clause affects the result of our experiment. We can set up a further experiment, subdividing these 8,993 cases (below) to examine the interaction between the transitivity feature of the second verb and the presence of the second adverbial clause. We might find that this sample behaves differently from the original one, an important rider to the original experiment.
Next, we examine the question of sampling. If we argue that cases of adverbial clauses within other cases are not at all independent from their parent, the worst case assumption would be that we should halve the observed and expected sample before performing the test. As we have seen, for every uppermost case there are 0.9 dependent cases below and at most 0.04 cases below that. If the strictly independent cases are a little more than 50% of the total then halving the sample is a reasonable approach.
The original chi-square result therefore simply halves (to 57.289), as do the various chi-square contributions. Since these are still easily significant, we can be sure that our original result is sound.
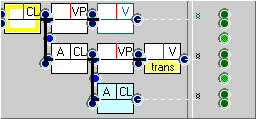
- The second problem is that there can be more than
one adverbial clause within the superordinate clause. The adverbial
case may be counted twice within the same structure while the
more general FTF without the adverbial is only counted once. Searching
for structures containing two following adverbial clauses
yields 327 cases out of 10,140, i.e., around 3% of cases
containing one adverbial clause also contain a second, for example,
“Now use [VP] the brake if necessary [CL1]
to stop it [CL2] <,>” (S2A-054 #22).
The FTF containing the adverbial clause will match separately for each additional clause. However, these are not really separate cases. We can either
- decrease this number by subtracting the results of each FTF with an additional adverbial clause, saying, in effect, that the ‘case’ is the overall clause, with the dependent variable being whether or not there is any following adverbial clause, or
- increase the total, in which case we are saying that these cases are independent.
Of these, the former is preferable. Note, however, that if, instead of simply detecting whether a constituent is present, a variable is specified by part of a constituent (e.g., by a feature), and that constituent can occur more than once, we have a different problem: if these distinct matches are collapsed to form a single case, which constituent do we choose? We could construct a further value (e.g., “multiple”), to classify these cases. In our example, the problem could not arise, because only one VP is permitted within a clause.
Finally, note that it is important to put these problems into some kind of numerical context. The second type of overlap only occurs in 3% of cases, so it may be considered within the margins of error. The first kind is not numerically trivial, occurring in around 90% of cases, and therefore should be investigated.
FTF home pages by Sean Wallis
and Gerry
Nelson.
Comments/questions to s.wallis@ucl.ac.uk.
This page last modified 28 January, 2021 by Survey Web Administrator.