Survey of English Usage
- Home
- About the Survey
- Staff
- Research Projects
- The International Corpus of English (ICE)
- ICE-GB
- DCPSE
- Corpus Queries
- Next Generation Tools
- The English Noun Phrase
- The English Verb Phrase
- Subordination in Spoken & Written English
- Teaching English Grammar in Schools
- Research Resources
- Software Sales
- Mobile Apps
- Events
- Summer School
- Study With Us
- Courses for Teachers
- Survey Archives
- Links
 DCPSE
DCPSE
The Diachronic Corpus of Present-Day Spoken English
funded by

DCPSE is a new parsed corpus of spoken English available on CD-ROM.
It contains more than 400,000 words from ICE-GB (collected in the early 1990s) and 400,000 words from the London-Lund Corpus (late 1960s-early 1980s).
The orthographic transcriptions have been normalised and annotated according to the same criteria. ICE-GB was used as a gold standard for the parsing of DCPSE. The parsing has been corrected by a variety of methods to provide as high a quality of result as possible (see the project pages for more information).
DCPSE is an incomporable resource for examining recent change in the grammar of spoken English.
 |
|
DCPSE Release 1 with ICECUP 3.1 has been released.
See the order form for details.
- At least 800,000 words (87,000 trees) of fully-parsed and annotated spoken British English from the 1950s to 1990s.
- Sociolinguistic information on texts, speakers and authors.
- Searchable with ICECUP 3.1.
- Supplied with Getting Started with ICECUP 3.1 (40pp) and extensive on-line help.
Download Release Candidate 2 of ICECUP 3.1.1 with DCPSE sampler
![]() The
latest version of our state-of-the-art ICECUP software is now available
as a beta release for download from our website ahead of the official
release in 2016.
The
latest version of our state-of-the-art ICECUP software is now available
as a beta release for download from our website ahead of the official
release in 2016.
The Release Candidate 2 package contains a new software codebase created with Visual Studio, and a new complete help file. Most importantly, the software has been reworked extensively to ensure that it is compatible with 64bit and 32bit versions of Windows, from XP to Windows 10.
![]() Watch a 'flash' preview demo of ICECUP
Watch a 'flash' preview demo of ICECUP
![]() Download the software
Download the software
There are numerous English corpora available.
WHAT IS SPECIAL ABOUT DCPSE?
DCPSE is fully grammatically analysed to the same standard as ICE-GB. All sentences in the corpus have been given a detailed parse tree.
DCPSE contains precisely 87,188 parse trees, comprising 885,436 words of English. The entire material is spoken.
This is the biggest single collection of parsed and checked orthographically transcribed spoken English material anywhere. The picture below shows ICECUP 3.1 browsing a text in the corpus.
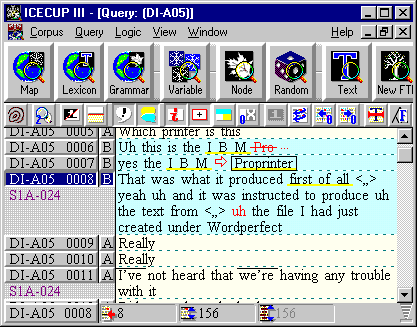
DCPSE has been fully checked. It was checked by linguists at several stages in its completion, using both a traditional ‘post-checking’ strategy and also by cross-sectional error-based searches. We do not believe that the analysis in the corpus is perfect, but it is not systematically imperfect - unlike the best parser output.
DCPSE comes complete with ICECUP. ICECUP allows you to perform a variety of different queries, including using the parse analysis in the corpus to construct Fuzzy Tree Fragments to search the corpus.
A sample corpus from DCPSE Release 1 and ICECUP 3.1 is now available for download. We also invite linguists to contribute to the development of cutting-edge corpus linguistics tools by participating in our beta programme.
Corpus text categories
| Face-to-face conversations (154) 494,000 words | Formal (28) 90,000 words | A |
| Informal (126) 403,000 words | B | |
| Telephone conversations (14) 47,000 words | C | |
| Broadcast discussions (28) 89,000 words | D | |
| Broadcast interviews (14) 43,000 words | E | |
| Spontaneous commentary (32) 95,000 words | F | |
| Parliamentary language (7) 21,000 words | G | |
| Legal cross-examination (3) 9,000 words | H | |
| Assorted spontaneous (7) 21,000 words | I | |
| Prepared speech (21) 63,000 words | J | |
Figures have been rounded down to the lower thousand of words. Only ~130,000 words are found in corpus texts with one speaker, the remainder are conversations or multi-speaker presentations.
This page last modified 14 May, 2020 by Survey Web Administrator.