A Methodological Survey
Introduction
Fuzzy Tree Fragments are a query representation that can be used in a number of different ways, from selecting examples to illustrate a point, to carrying out complex experiments.
Elsewhere we give a step-by-step guide to carrying out experiments using the ICECUP tool. Here we concern ourselves with discussing the relationship between exploration and experimentation, and identify future developments in computer-assisted experimentation. For an alternative recent overview, see Wallis 2014.
The 3A Perspective in Corpus Linguistics
 |
|
| Figure 1: 3 stages of corpus linguistics | |
Each of these stages represent a process of generalisation between original text and the evaluation of hypotheses. Each is knowledge intensive and approximate, and therefore cyclic. The arrows in the diagram represent a direction along which reearchers attempt to formalise their knowledge in an increasingly more sophisticated and generalised way, but we should also recognise that each process consists of a cycle.
- A very large amount of recent work in corpus linguistics concerns
annotation (Wallis 2007). Simply put,
annotation covers the entire process of constructing a corpus.
Typically it would include sub-processes of collection, transcription and standardisation, segmentation, a number of possible types of automatic processing, post-correction, and completion. The entire process is cyclic because, during the annotation of a corpus, or indeed afterwards, standards may need to be revised.
In order to maintain consistency, annotation is usually carried out in a centralised way, and only once a corpus is annotated is it distributed. Note that this is a pragmatic constraint, not a necessary principle. Different types of annotation may be added at different times, and annotation may continue after dissemination (second releases, etc.). Wallis & Nelson 1997 and Wallis 2003a describe the practical difficulties of carrying out a consistent parsed analysis of the ICE-GB corpus.
When a researcher carries out an experiment s/he will typically be motivated by a set of hypotheses. Note that in our figure, we distinguish between two distinct processes a researcher must undergo in order to relate corpus and hypothesis: first, abstraction, which is the elaboration of an abstract experimental model from the corpus, and second, the consideration of hypotheses against this model, what we refer to as analysis.
- Abstraction consists of the definition of an experiment
(or series of experiments), and the construction of an abstract
model or sample which may then be analysed.
The simplest type of model is just a table of totals called a contingency table. To construct a contingency table, one must carry out a set of queries over the corpus, where these queries are organised into dependent (predicted) and independent (predictive) variables. The scope of the model is defined by two aspects:- the (sub-) corpus and how it is sampled, and
- what precisely is under investigation - the case definition.
Detailed instructions on how to do this are given on our experiment pages.
A contingency table is not the only, or necessarily the optimum,
type of abstract model. If we step back a bit, a contingency table
is perhaps best thought of as one kind of summary of the experimental
dataset.
An experimental dataset consists of a set of cases rather than simply
a total number of each type of case. This notion is implicit in
our discussion of experimentation on our website. Contingency tables
are very simple and effective for small two-variable experiments.
However, if you want to consider more than one hypothesis
at a time, or look for other predictive variables, it is
more useful to explicitly abstract (define) and then explore this
dataset.
As we will see abstraction is also a cyclic process, where cases
in the corpus underpin the datapoints in our abstract model, and
one can repeatedly modify definitions and resample the corpus to
create a different dataset.
- Analysis relates this abstracted experimental model (sample)
to hypotheses.
Provided that an experimental data set captures viable linguistic concepts, hypotheses constructed on the basis of these concepts may be evaluated. One can test an existing hypothesis against the sample (classical empiricism) or generate new possible hypotheses from data (induction). Computation and statistical techniques may be automated, providing a technique known as Knowledge discovery (see below). Since it is necessary to understand the results of any such process by referring back to the original cases in their corpus context, this process is also cyclic.
We will see how this general ‘3A perspective’ helps us understand principles and approaches to working with corpus data in the following sections: corpus exploration, experimentation and knowledge discovery.
We commented that annotation is typically carried out in a centralised way and then disseminated. The corollary is that abstraction and analysis is typically carried out by individual researchers, published and debated as part of a community of active corpus linguists. Publishing a corpus establishes a common point of reference for this linguistics community. Thanks to the availability of cheap computing power on the desktop, corpus linguistics ceases to be an activity characterised by private research and threatens to become increasingly democratic.
Corpus exploration
Corpus exploration is motivated by the recognition that as corpora increase in size and detail, users of a corpus are necessarily less aware of the data recorded in the corpus and therefore become more reliant on tools in order to extract the knowledge (examples, statistical summaries, hypotheses, etc) they need. Increasing detail of annotation implies that (leaving regular experienced users aside), a user will typically not comprehend the entirety of the annotation in the corpus. Even where the annotation is documented (eg. in the form of a grammar), a user will not be aware of how it is recorded in the corpus.
This issue is not limited to grammar, but extends to any complex annotation scheme. It is not merely a problem for new users. It is central to corpus annotation and to corpus research. It also has an impact on pedagogical applications of corpora, both for teachers and students. As we shall see, the problem of exploration is also a problem of learning.
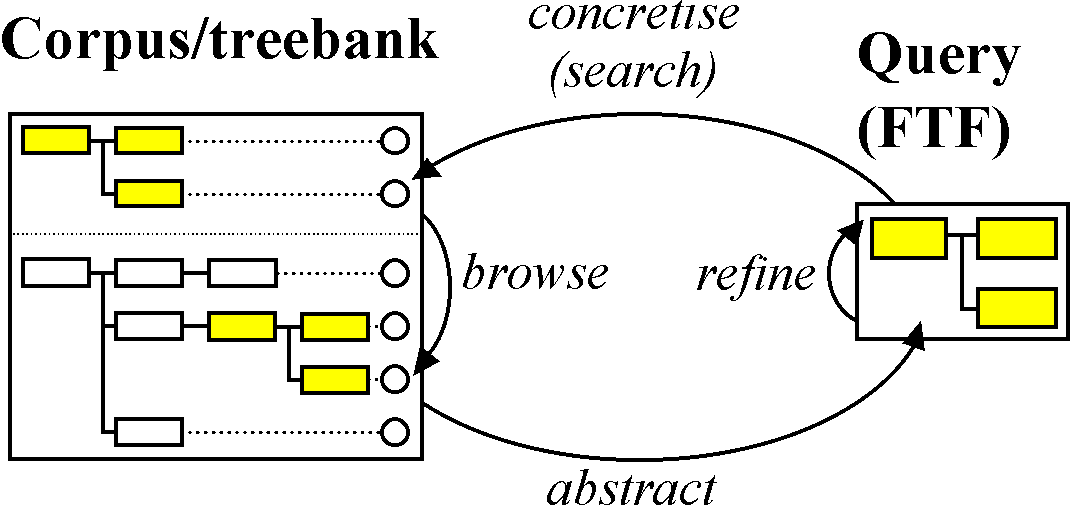
Figure 2: the exploration cycle
(click on image to magnify)
The solution which ICECUP III offers is to embrace what we term the exploration cycle, illustrated by the figure above.
The corpus may contain thousands or even millions of instances of a general construction, indicated by the highlighted nodes in Figure 2. The problem for a user is: how does s/he define a query that reliably identifies these constructions? The answer may involve a certain amount of trial and error, so exploration is necessarily cyclic.
- When a query is applied to a corpus in the form of a search (top arrow), the software identifies matching cases in the corpus.
- The user may then browse these cases (left arrow). If the user is satisfied with the results, the process can simply halt and the query may be reliably re-used, cited, and so forth.
- However, browsing the cases, the user may realise that the query is inadequately defined. The results may include cases that should not be included (false positives) and may need to be restricted. It may exclude cases incorrectly (false negatives), so the query may need to be made less restrictive or combined with an alternative pattern. Either way, the user must refine the query (right arrow).
- A further possibility is that users may wish to form a query from a specific example in the corpus (e.g., using the ‘FTF Creation Wizard’ facility). This is a type of abstraction process which is particularly valuable for users who wish to look for other examples of a particular construction. Typically an automatically abstracted query is quite concrete (over-specific) and may need further manual refinement and generalisation.
This cyclic perspective also requires a rather more complex and ‘forgiving’ software environment than simply providing a query process in isolation.
If the principal difficulty a user has in engaging with a parsed (or otherwise annotated) corpus is that they have to first learn the representation in order to carry out a query, then the exploration cycle is also a learning cycle for the user. One of the most crucial criteria for evaluating a query representation is that it is as comprehensible to the user as possible. Formal expressivity is valuable, but the meaning of any expression must be clear for it to be useful by non-specialists.
The query system we developed, Fuzzy Tree Fragments (FTFs, Wallis & Nelson, 2000), is based around this perspective. The central idea is that a grammatical query is best expressed as a tree-like model, because this directly reflects the representations one sees in the corpus. The query can be made more abstract by omitting nodes, elements etc, and by modifying the status of links between nodes (e.g. allowing two nodes to be unrestricted by sequence order, or not immediately adjacent).
A further advantage of using tree fragments is that there is a readily identifiable topological mapping between query and instance, as indicated by the figure above. Intuitively we recognise that the parent node of the FTF query on the right must match those corresponding parent nodes highlighted in the corpus on the left.
Corpus experimentation
There are, however, practical limits to corpus exploration as defined above. Exploratory techniques are principally concerned with the parallel evaluation of queries - ‘abstract cases’ - against cases in the corpus. Successful exploration allows us to specify queries which capture linguistically relevant concepts. However in order to carry out scientific experiments with corpora, simply capturing the correct realisation of a general concept is not enough.
Scientific experimentation, introduced in Wallis, 2003b and described in some detail here and Nelson, et al 2002, concerns the elaboration and evaluation of hypotheses. For practical purposes, a hypothesis is a general expression couched in concepts which may be evaluated against a corpus. To carry out such an evaluation, the concepts underpinning a hypothesis must be grounded in queries.
For example, consider the hypothesis that mood affects the transitivity of a clause.
For this to be evaluated experimentally, one must first specify that what is meant by the mood of a clause can be identified by applying a series of FTF queries for CL(x) where x is a member of the ‘mood’ feature class (in ICE), and likewise for transitivity. Moreover, we mean the mood and transitivity of the same clause, ie. the mood and transitivity of a clause is identified by evaluating FTF queries for CL(x, y) where x ε mood and y ε transitivity. The results, in the form of a table, may then be evaluated using the chi-square statistic.
In practical terms, then, evaluating any hypothesis typically means carrying out an enumerated series of queries. This single mood/transitivity experiment requires the application of 35 (5 x 7) distinct queries. If one would like to modify the definition of either ‘mood’ or ‘transitivity’, then this experimental model, or parts of it, would need to be recomputed. (Note one can collapse categories, for example, to ignore distinctions captured by the ICE account of transitivity, relatively easily.)
Secondly, one would also need to carry out more mechanical computation should we wish to introduce further variables, or to limit the experiment in some way. The main problem - that we are now working with groups of related queries, rather than a single query - remains. In effect, we are dealing with an experimental cycle ‘on top of’ the exploration cycle, as shown below.
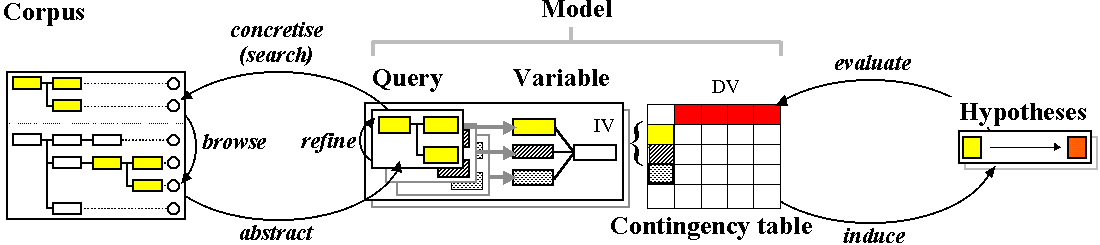
Figure 3: a simple type of experimental cycle
(click on image to magnify)
In this figure related queries are organised by the variables that they define and instantiate. In the experiment we have just seen the variable mood has a number of alternative values: {exclam, inter, imp, subjun, 0}. Similarly, the variable transitivity consists of a number of distinct classes. Some of these classes may be grouped together for the purposes of analysis. However, using ICECUP, changing any aspect of the definition of our model is quite difficult. For example, if one were to subsequently choose to subdivide clauses by the structure of the clause rather than by its given features, the entire sampling process would have to be carried out again. This is because ICECUP is primarily designed around exploration rather than experimentation.
A contingency table summarises, in the form of totals, a sample which is implicitly represented elsewhere. A contingency table is a clear way of illustrating how two discrete variables interact. It collects totals together in order to carry out a χ² test. However, in many circumstances it is valuable to identify these underlying cases.
In order to do this we must elaborate an experimental dataset. This dataset is the missing link, implied by the large curly bracket, between the variable definitions and contingency table in Figure 3. Figure 4 makes this explicit.
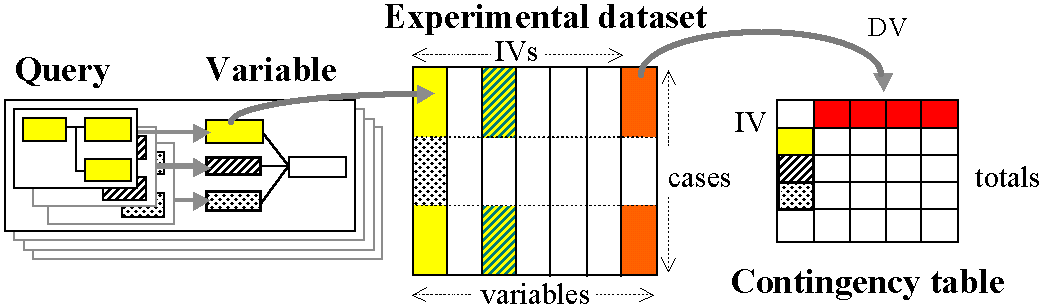
Figure 4: the experimental model, elaborated
(click on image to magnify)
Each case in this dataset represents a single instance of the linguistic phenomenon under investigation in the corpus. To ensure that no information is lost, each case cross-references the sentence in the corpus, with a further identifier to specify which particular case (eg. which particular clause) in the sentence we are concerned with. (Hence the definition of a ‘case’ is a prerequisite to the elaboration of an experimental dataset.) An abstracted dataset extends the idea of a concordance display, a way of viewing and distinguishing matching cases within text units, to include values of variables.
At present, the only way to do this is to export data from ICECUP into a spreadsheet, and then to list variables in other columns in the spreadsheet. Summing columns gives us totals in a contingency table.
However exporting data is an unsatisfactory procedure for a number of reasons. It can be difficult to elaborate variables, define new variables, resample cases or re-examine the data in the corpus to propose new variables. An export procedure breaks the cycle.
The solution should be obvious - to extend the exploratory platform into an experimental one, and incorporate the experimental cycle within the platform. Our Next Generation Tools project aimed to do precisely this.
If a researcher has the tools they need to carry out their research on the same platform they would not need to export data. Specifically, this means that we must provide facilities for the following:-
- defining variables from queries, both by top-down formal and bottom-up (n-gram type) approaches which use the corpus to enumerate the set of actually existing values,
- elaborating an experimental dataset, subdividing a set of cases by these variables,
- analytical procedures, both statistical and discovery-based.
One advantage of bringing the experimental process onto a single platfom is that it also makes discovery-based analysis procedures possible. These offer the possibility of automatically trying out many hypotheses, involving numerous possible independent (predictive) variables. We turn to this next.
Knowledge discovery in corpora
In a pilot study described in Wallis & Nelson 2001, we demonstrated the viability of statistically sound hypothesis detection in corpora. This paper established an approach and a number of concepts which have since proved to be highly productive. It enabled us to focus precisely on issues of experimental design as well as on the viability of hypothesis discovery.
- Hypothesis detection is a form of machine learning which considers statistically sound hypotheses in parallel (as there can be more than one explanation for a phenomenon) and identifies the most general and effective hypotheses.
We identified a research topic, defined a set of variables in terms of FTFs and sociolinguistic variables, and then wrote a simple procedure to automatically generate and output a regular dataset of abstract cases. This was then treated as input to a machine learning algorithm, which generates and evaluates hypotheses in the form of a set of parallel independent rules.
There were a number of limitations of this study, which are summarised below. Nonetheless it demonstrated that the technique was both viable and productive, discovering meaningful hypotheses involving combinations of variables that a researcher would not normally consider.
- Representation. The method uses discrete or hierarchical variables, and employs χ² to evaluate significance. Ordered or continuous-range values are not explored.
- Values must be given in advance. In the jargon, this is a ‘supervised’ type of machine learning. There may be a number of circumstances where it would be useful to try to construct a target variable by identifying clusters.
- The process involved exporting data. Typically the first thing a researcher would wish to do after a novel hypothesis is detected is to look at the cases in the corpus which support or challenge this particular interpretation. But this is difficult because the experimental dataset is not part of an experimental platform (as we discussed above).
Other weaknesses identified include the lack of computational support for the acquisition process from the corpus. Our sampling method was potentially problematic, as the structure of the dataset meant we could not address the question of case interaction. However, these issues are equally applicable to corpus experimentation, and are worthy of separate research.
The role of statistics
Statistical techniques include the application of statistical tests to evaluate hypotheses (for example, as described on our experiment pages and corp.ling.stats). But they also include line fitting and expressing uncertainty using confidence intervals.
Linguists have a number of problems in employing statistical methods to relevant research questions. There are problems on both sides of the linguistics/statistics divide.
- Many linguists are not trained in mathematics and statistics, and rely on off-the-shelf advice which may not be appropriate or optimal for their research question.
- Conversely, most statisticians work with data which is very different in structure from annotated corpora.
The blog corp.ling.stats includes a range of short explanatory blog posts, academic papers, slideshow presentations and spreadsheets, employing mathematical and statistical arguments focused on encouraging and supporting corpus linguistics research.
Statistical methods can be employed at all levels of the 3A hierarchy. They may be used inductively (usually alongside human decision making) to travel up the hierarchy.
- For annotation, a statistical algorithm might be used to predict sentence segmentation or recognise phrases and small clauses.
- Collocation and N-grams are a statistical approach to creating generalised patterns or queries, which might be used to aid abstraction.
- Conventional hypothesis testing is employed at the analysis level.
'Statistical algorithms' such as POS-tagging or n-gram abstraction are really a combination of statistical calculations within computational processes.
References
| 1997 | Wallis, S.A. and G. Nelson. Syntactic parsing as a knowledge acquisition problem. Proceedings of 10th European Knowledge Acquisition Workshop, Catalonia, Spain, Springer Verlag. 285-300. | |
| 2000 | Wallis, S.A. and G. Nelson. Exploiting fuzzy tree fragments in the investigation of parsed corpora. Literary and Linguistic Computing 15, 3: 339-361. | |
| 2001 | Wallis, S.A. and G. Nelson. Knowledge discovery in grammatically analysed corpora. Data Mining and Knowledge Discovery, 15: 307-340. | |
| 2002 | Nelson, G., Wallis, S.A. and Aarts, B. Exploring Natural Language: Working with the British Component of the International Corpus of English, Amsterdam: John Benjamins. More... | |
| 2003a | Wallis, S.A. Completing parsed corpora: from correction to evolution. In Abeille, A. (ed.) Treebanks: building and using syntactically annotated corpora, Boston: Kluwer. 61-71. | |
| 2003b | Wallis. S.A. Scientific experiments in parsed corpora : an overview. In Granger S. & Petch-Tyson, S. (ed.) Extending the scope of corpus-based research: new applications, new challenges, Language and Computers 48. Rodopi: Amsterdam. 12-23. | |
| 2007 | Wallis, S.A. Annotation, Retrieval and Experimentation. In Meurman-Solin, A. & Nurmi, A.A. (eds.) Annotating Variation and Change. Helsinki: Varieng, UoH. » ePublished | |
| 2014 | Wallis. S.A. What might a corpus of parsed spoken data tell us about language? In: Proceedings of Olinco 2014. Oloumouc, Czech Republic. » ePublished corp.ling.stats |
FTF home pages by Sean Wallis
and Gerry
Nelson.
Comments/questions to s.wallis@ucl.ac.uk.
This page last modified 28 January, 2021 by Survey Web Administrator.