Performing experiments using FTFs
Introduction: What is a scientific experiment?
Introduction
If you want to find examples of a grammatical construction in a parsed corpus such as ICE-GB you can perform an FTF query, described on other pages on this site. Performing a query will produce a (potentially very long) list of results, consisting of a sequence of sentences or ‘text units’.
Within every sentence an FTF will match in at least one distinct arrangement (a ‘hit’ or case). Note that if elements within the FTF are common or the structure is flexible, there can be many hits per sentence.
Here we address the following question:-
How should researchers employ grammatical queries to carry out experiments on a parsed corpus?
The question is perfectly valid. Provided that the corpus is collected systematically, and annotated consistently and in good faith, there is no particular reason why an experimental approach cannot be applied to a corpus, even a parsed one. For some comments on the philosophical implications of this, see here. (Note for the avoidance of doubt, the term experiment on these pages is used to mean a natural experiment rather than a laboratory experiment, see below.)
The question is also very important. It is one thing to find examples of a particular construction in a corpus, and quite another to make any generalisations about the presence of such constructions in contemporary British English or in English in general. Moreover, examples merely indicate the existence of possible phenomena, they do not explain under which circumstances they appear. The latter requires both an experimental method and a clear theoretical defence.
ICECUP 3.1 supports the construction of some simple tables and the collection of frequency statistics. However in many of the examples described here you will have to perform the process of extracting data from the corpus by hand. (We believe that automating many of the procedures would be highly advantageous, for a number of reasons, and this is the subject of the Next Generation Tools project.)
A note of caution: these pages are written for linguists (including PhD and MA students) wishing to experimentally investigate parsed corpora. The explanations necessarily touch on technical issues in statistics. This is not meant to be an introduction to the chi-square test, or the assumptions and ramifications of the test. If you are unfamiliar with chi-square, you can look at other pages on the web or a good experimentalist workbook.
![]() Slides from the TALC workshop in Bertinoro (TALC
02), which discussed experimental design in corpora, are also
available as a PDF file.
Slides from the TALC workshop in Bertinoro (TALC
02), which discussed experimental design in corpora, are also
available as a PDF file.
This page makes some introductory comments about experimental design. The following pair of pages summarise the general method and common pitfalls you should be aware of if you use FTFs in experimentation. A second pair of pages discusses the more complicated problem of examining how two grammatical aspects of a phenomenon interact. (NB. You should read these pages in order.)
Many of these questions are, in fact, central to the investigation of any corpus, including plain text and tagged corpora. The problem simply becomes more acute with a parsed corpus and rapid retrieval software like ICECUP. As we shall see, it also becomes easier to identify a hierarchy of linguistic choices when a detailed grammatical analysis is present.
It is easy to collect tables of frequencies. It is less easy to design experiments to make sense of the numbers.
| Statistical health warning: |
Performing an experiment is not a substitute for thinking
about the research problem. You need to (a) get the
design right and (b) relate the results back to
a linguistic theory. These pages are meant to help you get the design right. |
What is a scientific experiment?
Answer: it is a test of a hypothesis.
A hypothesis is a statement that may be believed to be true but is not verified, e.g.,
- smoking is good for you
- dropped objects accellerate toward the ground at 9.8 metres per second squared
- ’s is a clitic rather than a word
- the word “whom” is used less in speech than writing
- the degree of preference for “whom” rather than “who” differs in contemporary spoken and written British English
In each case, the problem for the researcher is to devise an experiment that allows us to decide whether evidence in the real world supports or contradicts the hypothesis. Compare examples 4 and 5 above. If a statement is very general
- it is hard to collect evidence to test the hypothesis and
- the evidence might support a variety of other explanations.
So we need to “pin down” a general hypothesis to a series of more specific hypotheses which are more easily testable. The art of experimental design is to collect data appropriate to the research hypothesis. We will discuss how to collect data from the corpus in the following page.
In brief, a simple experiment consists of
- a dependent variable, which may or may not depend on
- an independent variable, which varies over the normal
course of events.
As a convenient shorthand, we will also refer to the independent variable as the “IV” and the dependent variable as the “DV”.
(By the way, it is also possible to have experiments with more than one possibly contributing factor (IV) or more than one kind of outcome (DV) but it is always better to keep it simple. In any case, such “experiments” are carried out as a series of simpler experiments.)
Thus in example 5, the independent variable might be ‘text category’ (e.g., spoken or written), and the dependent variable, the number of times “whom” is used where applicable, i.e., when either “who” or “whom” could be used in the text.
A statistical test lets us measure the strength of the correlation between the dependent and independent variables.
- If the measure is small, the variables are probably independent, i.e., they do not affect one another;
- if large, it means that the variables correlate, i.e., they may be dependent on one another.
Does a significant result mean that we have proved our hypothesis?
Strictly, no. There is always the possibility that something else is going on. A correlation does not indicate a cause.
For example, taken across a population, height (A) and educational attainment level (B) may correlate. But growing taller does not increase one’s thirst for knowledge, nor one’s ability to pass exams. The reverse implication may be true, i.e., that knowledge tends to improve diet and well-being. |
|||
Other root causes (e.g. distribution of wealth, C), might be said to contribute instrumentally to both height and education simultaneously. (One experimental technique is to eliminate any such possible cause by obtaining a sample of similar wealth and performing the experiment again. However, the result would only apply to the population from which the sample was taken. This method is what is meant by reductionism.) |
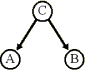 |
Here we must make a distinction between ‘laboratory’ experiments and natural experiments, sometimes called ex post facto studies. In a lab experiment researchers can (to some degree) control experimental conditions in order to limit the effect of alternative hypotheses in advance. The disadvantages with lab experiments are that they may be over-constrained (e.g. reading from a screen with the lights off with the subject’s head anchored to apparatus) or narrow and unrepresentative (e.g. data based on a particular collaborative task). Corpus studies by contrast have the potential to overcome some of these problems.
In our case, we must use a linguistic argument to try to establish a connection between any two correlating variables.
Note: Do not claim that your results demonstrate the ‘probabilistic reality’ of a phenomenon. A statistical test is based on a mathematical model that estimates how likely it is that an observed deviation from an expected distribution would occur by chance, given certain assumptions.
What about the converse? Does a non-significant result disprove the hypothesis?
The conventional (Popperian) language used to describe an experiment is couched in double negatives. We refer to a “null hypothesis”, which is the opposite of the hypothesis that we are interested in. If a test does not find sufficient variation, we say that we cannot reject the null hypothesis. This is not the same as saying that the original hypothesis is wrong, rather that the data does not let us give up on the default assumption that nothing is going on.
![]() More comments on the philosophy of corpus experimentation are available
here.
More comments on the philosophy of corpus experimentation are available
here.
So, what use is an experiment?
Experiments allow us to advance a position. If different bits of evidence point to the same general conclusion, we may be on the right track.
Designing an experiment
An experiment consists of at least two variables: a dependent and an independent variable. The experimental hypothesis, which is really a summary of the experimental design, is couched in terms of these variables.
Suppose we return to our example 5. Our dependent variable is the usage of “whom” versus the usage of “who”, our independent variable is the text category. Suppose that we take data from ICE-GB, although we could equally take data from other corpora containing spoken or written samples. NB. The size of the two samples need not be equal if you work with relative frequencies (see the next section).
Our experimental hypothesis is a more specific version than our previous one, i.e.,
- the word “whom” over “who” varies in usage between spoken and written British English sampled in a directly comparable way to ICE-GB categories.
 |
|
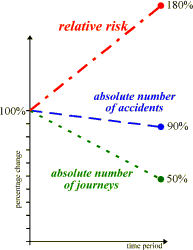
| A hypothetical example: changes in relative and absolute risk | |
Note that we are not suggesting looking at the absolute frequency of “who” or “whom”, e.g., the number of cases per 1,000 words. Rather, we should examine the relative frequency of “whom” when the choice arises.
Suppose someone tells you that train journeys are becoming safer. Between 1990 and 2000, they say, the number of accidents on the railways fell by ten percent. But what if the number of journeys halved over the same time period? Should you believe their argument?
The relative risk of injury (assessed, in this instance, per journey, but you could also consider per distance travelled instead) has increased (by 90/50x100% = 180%, see graph), not fallen.
- An absolute frequency tells you how frequent a word is in the corpus. But the reason that a word is there in the first place might depend on many factors that are irrelevant to the experimental hypothesis.
- Using relative frequencies focuses in on variation where there is a choice. The bad news is that you may need to check the examples in the corpus to see if there really is a choice in each case. If you use other annotation, such as tagging or parsing, to classify your cases, you may need to double-check this. (So, in case you were wondering, we haven’t given up on naturalistic study of the corpus just yet.)
If you are examining a parsed corpus like ICE-GB and are trying to investigate explicitly represented grammatical phenomena (i.e., the queries can be represented as an FTF or series of FTFs), then constructing a set of choices need not be especially difficult (see the issue of enumeration). If you have a large number of cases, you can rely on the parsing, provided that there is not a systematic bias in the annotation (i.e., either the corpus has been hand-corrected or uncertain choices have been resolved at random). Annotation errors that are systematic represent a bias, those that are random are noise.
In our example on the next page, the use of relative frequencies means that the expected distribution is calculated by scaling the total “who+whom” column. If we calculated it on the basis of absolute frequencies, the expected distribution would be merely proportional to sample size, and the result would be much more easily skewed by sampling differences between subcorpora.
Two pieces of good news
In other words, one of the common criticisms of corpus linguistics, namely that it consists of atheoretical frequency counting, is removed. Secondly, focusing on an individual choice tends to reduce the possibility that detected variation is due to sampling, because any such sampling bias will affect the probability of the choice to a greater extent than the probability of one decision over another. (NB. This said, you should always aim for a representative sample.)
A methodological continuum
Our methodological position is located somewhere between two polar opposites: exemplar-based introspection and the reporting of absolute frequencies in the absence of a context. From our point of view, the upper bound of an acceptable method is illustrated by the clause experiment (does the mood affect the transitivity of a clause?). Cases in this experiment (clauses) occur in a variety of distinct linguistic contexts where the factors affecting the correlation of the two variables (mood and transitivity) will also vary from situation to situation. Such an experiment is really too general to form any definite conclusions. The lower limit of our empirical approach is where we have a single linguistic choice and sufficient data to permit a statistical test. We will see this kind of experiment later. Note that the issue of specificity (of the linguistic context) need not necessarily be defined by only grammatical criteria.
![]() As we shall see, we can explore
a set of experimental hypotheses by working from the top, down,
or from the bottom, up.
As we shall see, we can explore
a set of experimental hypotheses by working from the top, down,
or from the bottom, up.
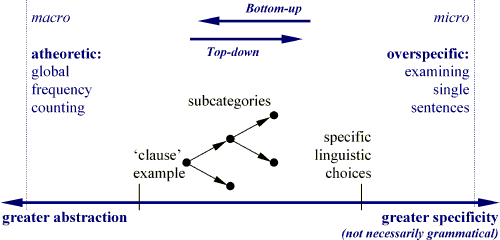
The methodological continuum in corpus linguistics
(click on image to magnify it)
This kind of corpus research is based on counting tokens rather than types. That is, our evidence is frequency data from a natural sample, each case counted irrespective of whether it is unique. This experimental design is distinct from studies of dictionary or lexicon data concerned with the frequency of unique types.
The sample chosen for an experiment determines the theoretical ‘population’ you can generalise a significant result to. A significant result in a corpus can be generalised to a comparably selected population of sentences. A significant result in a lexicon study (where corpus frequency data is not taken into account) generalises to a comparably selected population of lexicon entries. If the lexicon is derived from a corpus, then this allows us to predict that, were a lexicon to be compiled using the same process from a comparably sampled corpus, the results would be likely to be repeated. If the lexicon is derived from dictionaries, then the dictionary compilers’ biases must be taken into account.
Experiments with a parsed corpus
The issue of relating two or more grammatical elements together becomes central when we consider the question of performing experiments on a parsed corpus.
- It is easier to be more precise when establishing the grammatical typology of a lexical item, saying “retrieve this item in this grammatical context”. We can also vary the preciseness of our definitions by adding or removing features, edges, links, etc.
- It is easier to precisely relate two items, e.g., “the and man are both part of the same noun phrase”.
Against this perspective is the objection that an experiment must necessarily be in the context of a particular set of assumptions, i.e., a specific grammar. This does not rule out the possibility of scientific experiments, however, but means that we must qualify our results – “NP, according to this grammar”, etc. We discuss this issue at greater length here. In a parallel-parsed corpus one could study the interaction between two different sets of analyses (although in practice the workload would be very high unless more of the task could be automated).
In ICECUP, we use Fuzzy Tree Fragments to establish the relationship between two or more elements. Moreover, we can study the interaction between grammatical terms. This is discussed in some detail on the final pair of these pages. We turn first to a slightly simpler problem: how to determine if a socio-linguistic variable affects a grammatical one.
![]()
FTF home pages by Sean Wallis
and Gerry
Nelson.
Comments/questions to s.wallis@ucl.ac.uk.
This page last modified 28 January, 2021 by Survey Web Administrator.