How FTFs match trees
Loose tree fragments (using the 'Ancestor' relation)
The previous examples have one thing in common: the location of the parent node is specified. But sometimes it is necessary or advantageous to specify that a parent in an FTF is not immediately related to a child. One reason for doing this is to allow less strictly “tree-like” structures to be built, such as sequences of tags and words. In the following examples we look at this in more detail.
A loose tree fragment with genuine siblings
Suppose we look for clauses which dominate ordered ‘auxiliary, verb’ sequences:. An appropriate FTF is given below, left.
Again, create a ‘New FTF’ and add 'two child nodes after'. Label the first node an “operator“ (function), ”auxiliary” (category) and the second node as “main verb“ and “verb” respectively. Then, set both of the parent links to ‘ancestor’ (click on the cool spot on the link).
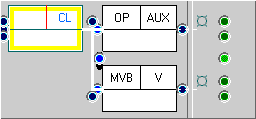
The FTF obviously matches the following tree (S1A-010 #149) twice. However, there is also a third, not so obvious match.
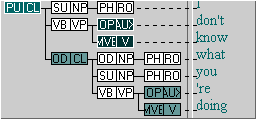
- The highlighted match is the entire clause “I don’t know what you’re doing”, where “don’t know” is the ‘auxiliary, verb’ pair.
- The second match is the direct object clause “what you’re doing”, with “[a]re doing” as the ‘auxiliary, verb’ pair.
- The third, and less obvious, match is the entire clause “I don’t know what you’re doing”, with the auxiliary and verb being represented by “[a]re doing”, again.
What if you just want to match cases where the nearest clause to the pair is found?
Here you have to apply observation and a little grammatical knowledge. Since ICE is a complete, rather than skeleton grammar, there will always be an intermediate (VP) node between the clause and the verbal elements. You can therefore introduce this intermediate node into the FTF and then insist that all parent-child relationships are direct ‘parent’ links.
Another possibility is to try to restrict how the clause node matches in other ways.
For example, if you were just interested in a list of different verb and auxiliary pairs which were within a clause, you could require that the clause matched the root (in which case it would exclude match (2) above). This would also exclude cases where the root node was not a clause, however. (In case you were wondering, FTFs do not offer the option of a ‘nearest ancestor’ link because such a link is by definition procedural and FTFs are declarative.)
In this example, the FTF’s ‘child nodes’ are genuine siblings in the tree, i.e., they share the same parent. This restriction is entailed, not by the ‘Parent’ link, but by the status of the ‘Next child’ link. ‘Immediately after’ means “immediately after in the sequence of siblings in the tree,” and therefore implies that the nodes share the same parent. Note that this property is shared by three other values of ‘Next child’: ‘after’, ‘just before or just after’ and ‘before or after’. (This property is implied by the ‘stem’ of the arrow).
If you want to allow siblings to match tree nodes regardless of their parenthood, you would have to use a different ‘Next child’ option. Thus, if two nodes are connected together with ‘Next child = <unknown>’ (and the ‘ancestor’ parent link is employed) then no restriction is placed on their relative position. However, this situation can be too weak in many circumstances. A more desirable constraint would be to state that the two nodes must be on different branches of the tree.
A tree fragment with siblings on different branches
The restriction that two nodes must be on different branches can be rephrased simply, as meaning that one node cannot be the parent of the other. The nodes matching each sibling cannot share a path to the node matching their common parent. This option is more general than ‘before or after’, because it does not require a common parent, and is drawn like the white double arrow link without the common stem.
The FTF below left looks for examples of clauses containing a NP acting as a direct object (note that this is directly linked to the clause) and, somewhere within the clause - but not within the direct object - a noun phrase head.
Create a three-node FTF in the normal way, i.e., with a ‘New FTF’ command and 'two child nodes after'. Label the nodes as shown using the ‘Edit node’ command (F2). Next, click on the cool spot for the ‘Parent’ link for the noun phrase head node and then set the ‘Next child’ relation to ‘different branches’ either by clicking down on the cool spot for ‘Next child’ several times or invoking the pop-up menu and setting the value.
Moreover, we can insist that the NP head must follow the direct object in the textual sequence by introducing the ‘Next word’ link. (This works because (a) the ICE grammar is a phrase structure grammar, which denies the possibility of crossing links, and (b) the ‘Next word’ link is interpreted to mean that there is a word under the first node that precedes a word under the second.)
Finally, rotate the ‘Next word’ link until it reads ‘after’ (white arrow).
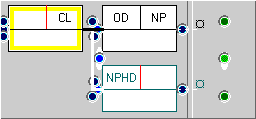
You should get quite a lot of matches. The tree below, right (S2B-002 #36), contains several examples.
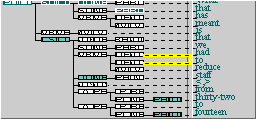
There are three distinct matches in this tree.
- The first matches the subject clause “What that has meant is...”, where the direct object is realised by “what” and the noun phrase head “that” is in subject position.
- The second matches the subject complement clause node “...is that we had to reduce staff <,> from thirty-two to fourteen” and the direct object is realised by “staff”. The isolated noun phrase head element is part of an adverbial prepositional phrase “from thirty-two”.
- The third match is identical to the second, save the position of the noun phrase head, which is in the other prepositional phrase, “to fourteen”.
As we discussed before, you should be careful using these ‘loose’ links when you are formalising your experimental design so as to minimise the number of multiple overlapping instances.
We recommend that you experiment with structural variations on this theme using ICECUP. Try each of the following in turn, resetting the link after the experiment.
- What happens if ‘Next child = different branches’
is set to <unknown>?
You get many more matching cases, including those where the noun phrase head is the head of the direct object NP. The ‘Next word’ restriction means that there must still be a node prior to the head within the NP: a determiner, for example.
- What happens without the word order restriction, i.e., ‘Next
word = <unknown>’?
You get additional cases with NP heads prior to the direct object.
- What happens if we weaken the restriction that the clause is
the parent of the direct object?
You obtain many more cases per tree, and eventually, the “out of memory” error. This is because the number of distinct matching arrangements can increase combinatorially.
The following (quite mild) example illustrates the principle. The first three highlighted locations, (reading left to right) match the clause element (as the clause can be any distance “above” the direct object “your S” which is hidden to the right). The two rightmost locations match the NP head element. Since all three locations of clause are legitimate for both positions of the NP head, there are six matches in total. Now suppose there are more than one direct object node. This is called “underspecifying” your search in the help manual.
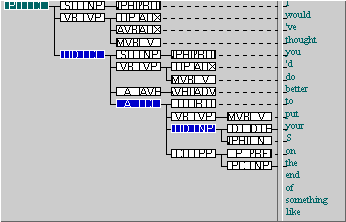
The problem can be avoided by restricting the location of nodes in various ways (as we did in our example). You should link elements together immediately if at all possible, even if this means introducing new nodes. You should avoid introducing loosely connected nodes which are very generally specified (clauses are common, “empty” unspecified nodes will match anything). The following advice is reproduced from the help manual.
A general solution to the problem of underspecification
|
None of the above necessarily means that you should always avoid the ‘different branches’ or <unknown> options, or stick to using the ‘immediate parent’ link. If you want to express a query consisting of two tightly-bound fragments that are connected together only loosely, the ability to specify that neither is above the other can be very useful. It is just a good idea to be sure that neither of the fragments are over-general.
Text fragments, reconsidered
One situation where ‘Next child’ is routinely set to <unknown> is when you want to specify a text fragment. The idea is that all nodes which might have words associated with them are specified in the tag, or leaf position, and, if the query will match more than one word or tag in a sequence, the set is grouped together by ancestor links under a common node set to ‘Root = yes’. (We considered single word FTFs and tagged-word FTFs in the first section.) The sequence itself is specified by ‘Next word’ relations, which ignore tree structure.
It can be useful to consider the query as a ‘comb’, or ‘hedge’, instead of a ‘tree’. Structure may be added by moving up the tree from the leaves toward the root.
The following is a simple example of a two-element text fragment which finds examples of “this” followed by a verb, as in “This is too salty.”[S1A-010 #86].
In the ‘Text Fragment’ window, type the word “this”. Then, press <SPACE> and hit the ‘Node’ button. Position the input caret (blinking cursor) between the angled brackets and type “V”. The query should look like this: “this <V>”. Then press the ‘Edit’ button.
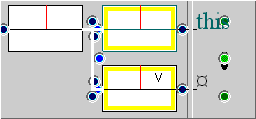
The FTF should look like this. You will see that the upper node is specified as the root of the tree (matching the ‘PU,CL’ element on the right), while the nodes for “this” and the verb are specified as leaves. ‘Parent’ links are set to ‘ancestor’ and the ‘Next child’ link is, as we suggested, <unknown>. We do not wish to restrict the query grammatically in this case (we might subsequently choose to do so, but that is another matter). Finally, the ‘immediately after’ arrow indicates that the verb must immediately follow the word “this” in the text sequence.
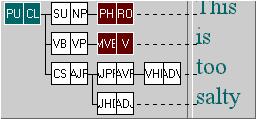
The FTF matches a series of examples, including the one shown here. Although there is considerable ambiguity introduced on the tree side - empty nodes, ancestor links, unspecified ‘Next child’ relations - the query is not underspecified (see above). For one thing, lexical items tend to be more specific than a simple node specification.
To give you an idea, in the complete ICE-GB corpus there are, including capitalisation and spelling variants, over 46,000 distinct lexical items (= over 63,000 word+tag tokens). But there are ‘only’ around 7,500 distinct nodal patterns (complete denotations of function, category and set of features).
Moreover, the nodes are bound to specific positions in the tree (root, leaf) and the ‘immediately after’ link is employed. As a result, the leaf nodes are related to each other via the sentence. This dramatically reduces the ambiguity.
Setting up an FTF like this from scratch using the FTF editor is quite difficult, and it is easy to make mistakes (typically, forgetting to specify the ‘Root’ or ‘Leaf’ positions, see the help manual). The “Text fragment” query window constructs queries like this very easily. You can then modify the query, for example, by laddering up, but note that if you add elements you will need to set links appropriately. The help manual contains a worked example of this.
FTF home pages by Sean Wallis
and Gerry
Nelson.
Comments/questions to s.wallis@ucl.ac.uk.
This page last modified 28 January, 2021 by Survey Web Administrator.