Survey of English Usage
- Home
- About the Survey
- Staff
- Research Projects
- The International Corpus of English (ICE)
- ICE-GB
- DCPSE
- Corpus Queries
- Next Generation Tools
- The English Noun Phrase
- The English Verb Phrase
- Subordination in Spoken & Written English
- Teaching English Grammar in Schools
- Research Resources
- Software Sales
- Mobile Apps
- Events
- Summer School
- Study With Us
- Courses for Teachers
- Survey Archives
- Links
Next Generation Tools
Next generation tools for linguistic research in grammatical treebanks
Ref: R 000 23 1286
Institution: University College London
Department: Department of English (Survey of English Usage)
Principal investigators: Bas
Aarts and Sean Wallis
Period: 1 January 2006 to 31 December 2007
Non-technical summary
The research was to develop a software environment for carrying out experimental research in corpus linguistics, with a particular emphasis on parsed text corpora. Corpora are collections of (transcribed) spoken and written passages, annotated in a number of different ways. A parsed corpus is one where the grammatical structure of each sentence is included. As corpora grow in size and complexity (typical parsed corpora have around 1M words), corpus linguistics research becomes increasingly dependent on computer software support.
Previous research focused on developing an effective, linguistically meaningful, grammatical query system. This transformed possibilities in corpus linguistics. Searches which had previously taken weeks could be performed in seconds. Simple experiments could be constructed around these queries, results being analysed manually. Where a previous generation of researchers had focused on studies of distributions and difference between samples, or used a corpus as a starting point for philosophical discussions of language, the parsed British component of the International Corpus of English (ICE-GB) and its accompanying International Corpus of English Corpus Utility Program (ICECUP; corpus exploration software), can be used to investigate how one aspect of a linguistic choice can affect another. This also applies to the Diachronic Corpus of Present Day English (DCPSE).
While the range of potential research possibilities continues to expand, using previous software experiments require careful planning, are difficult, time consuming and error-prone. There is no easy fit between directed searches and enumerative approaches to research (collocations and n-grams). And the separation of statistical analysis from the corpus means that it is difficult to determine how alternative hypotheses overlap.
This project undertook to develop a new system supporting a complete experimental cycle, consisting of four stages:
- the definition of an experiment consisting of one or many research questions;
- the abstraction of a sample from the corpus;
- the analysis of the sample and the testing of hypotheses, and
- the evaluation of experimental results against the corpus.
Linguists define their experiment in the first stage. This definition contains two or more variables, centred on a particular linguistic event under investigation: a word, phrase, clause, etc. This event is characterised by a ‘case definition’ common to every grammatical variable. It fixes every case in the sample to a unique point in the forest of corpus trees.
Variables can lexically or grammatically classify cases, recognise the presence of particular structure(s) and count sub-elements. Sociolinguistic variables can be imported and edited.
Once formulated, the experimental design is applied to the corpus to abstract the sample. The program examines every case in the corpus and applies each variable in turn to obtain a value. The sample is a table of values, one row for each case in the corpus.
Linguists can browse the sample and view trees in the corpus using the ICECUP interface. They can inspect how the sample matches cases in the corpus, down to a particular node or word in a tree. If problems are found they can adjust their experimental design.
The next stage is to analyse the sample. The software supports
a statistically sound knowledge discovery system for exploring many
hypotheses consisting of multiple variables. This process explores
the possible combination of variables and values, constructing hypotheses
for testing against the sample, effectively carrying out many mini-experiments.
Every statistically significant hypothesis is considered for decidability
(whether it definitively predicts a value of the dependent variable),
and is scored on a number of criteria, including accuracy and coverage,
and ordered by quality.
The final evaluation stage concerns the process of helping linguists
understand their experimental results. Hypotheses found by the analysis
process are found in a panel in the sample viewer.
The panel presents hypotheses with statistics and a ‘coverage map’ that graphically summarises the distribution of cases explained by the hypothesis. Hypotheses explaining distinct or similar sets of cases in the sample can be seen.
In addition, linguists may opt to limit their sample view to only cases that support or contradict a particular hypothesis. They can examine these cases thoroughly, to the level of a particular element in the tree, hopefully sparking new research ideas.
Linguists arrive at the end of this experimental cycle (definition, abstraction, analysis and evaluation) with more knowledge than they started. Provisional results may be improved upon and definitions finessed.
One research challenge addressed in the project concerns the fact that grammatical or lexical elements in running text are not independent in origin but random samples assume cases are statistically independent. Experimentalists face a choice: either require cases in the sample to be sourced from different texts or recordings – or try to model the relative independence of cases. The disadvantage of the first option is that samples will be small and results will likely miss low-frequency phenomena.
We therefore implemented an ‘a priori’ model for the relative independence of cases, based on the assumption that the interaction between cases declines over grammatical distance. This type of assumption has a number of important implications, not least that a given grammar in a corpus may be empirically verifiable by examining patterns of interaction (see 8 below).
The approach is highly general and extensible. We use the medium of grammatical investigations into parsed corpora because data is available, a community of linguist end-users exist, and because there is a substantial existing literature for comparison. The addition of further levels of annotation in corpora offer the promise of future work in constructing theories that relate these levels to grammar.
The status of the software is that it is now available as a beta release, with the first full release in the Summer of 2008. We will disseminate it for free from our website and offer it as a free upgrade to current users of our corpora. It comes with a ‘Getting Started’ guide of some fifty pages including tutorials and discussion, which will be published in a number of forms, including as an extension to the on-line help manual. We envisage this will form the basis for a book on experimentation with parsed corpora.
![]()
Full report
1. Background
The advent of parsed corpora ('treebanks') raises new possibilities in linguistic research. A parsed corpus is a database of texts where every sentence is given a grammatical analysis in the form of a tree.
Such corpora are difficult to construct, but are sources of three important types of linguistic evidence. The first of these is, simply, frequency evidence of known phenom-ena, lexical and grammatical. The second is evidence of unknown phenomena that might complete an account of grammar or improve the coverage of algorithms. Often these are discovered in the process of attempting to apply a given grammar to a corpus.
Increasingly, however, linguists are beginning to pay attention to a third type of evidence. This is evidence of interactions between one linguistic event and another. This type of investigation is interesting for a number of reasons.
First, parsed corpora provide a resource to unpick the way that one linguistic choice leads to another. Grammar takes it for granted that language utterances form a connected whole. But until a parsed corpus is investigated in this way, it is impossible to see how one linguistic choice impacts on another. Thus, the first motivation is as a means to verify known rules (e.g., agreement rules) and discover new ones. This is valuable for teaching purposes, writing monographs on grammar, and so forth. It was this concept of studying grammatical interaction that motivated this project.
A second motivation concerns future annotation in corpora. The ICE-GB and DCPSE corpora are annotated thoroughly for grammar, but this could be extended. Parsed corpora may gain further levels of annotation, including (for example) features and relations covering pragmatic, discourse and semantic levels.
During the course of this research we identified a second type of interaction study with a different aim - the empirical verification of grammar. See Section 8 below.
The ability to investigate the interdependence of linguistic events across grammar and pragmatics (for example) opens up new avenues of research (Wallis 2008c, in press). A corpus annotated with two alternative grammars could be contrasted in terms of whether one grammar or another captured the same linguistic event reliably.
2. Objectives
The objective of this project was to develop a general purpose research platform for carrying out experiments in parsed corpora. The aim was for this platform to be usable by linguists who are not scientifically trained or computer programmers, but maximally exploit computational power.
The platform is constructed on top of a mature software platform developed for exploring parsed corpora. The ICECUP III (Nelson, Wallis and Aarts 2002) codebase contains a number of tightly integrated tools, at three distinct levels:
- overview tools (corpus map, lexicon and grammaticon) exploring sets of queries;
- a query results browser viewing sets of cases. This displays matching cases and sentences, and the results of individual queries (supporting concordancing, context, word-wrapping, inline annotation, etc.), and
- a tree viewer for exploring an individual case, a sentence or grammatical tree.
Alongside these tools are an editor for a grammatical query system, Fuzzy Tree Fragments (FTFs), and a range of search tools.
In the original proposal we explained how the ICECUP III platform is sufficiently powerful to permit simple experiments on the grammatical analysis. The approach, described at length in Nelson et al. (2002), is to draw up a contingency table, apply separate FTF queries for every combination of grammatical feature, and then populate the table with the results. We noted that such a method is labour-intensive and error-prone, and thus difficult to scale.
Wallis (2008b; Section 1.2) summarises our motivation and presents our 'wish list'. ICECUP III was designed for exploration, not experimentation. Experiments are burdensome although the computer could clearly help. We wanted to be able to contrast multiple explanations for the same phenomenon and define multi-variate experiments involving both quantities and qualities. Statistical tests should be applied by the software automatically and without exporting data, and results should be evaluated against the corpus. Finally, we wished to address the problem that cases may not be strictly independent from each other, something that has been concerning us for a number of years. Only an integrated platform would permit this to be properly considered.
Our objectives were to build a complete system supporting the experimental cycle, from design through abstraction and analysis to evaluation, where tools are tightly integrated into this platform. Such a system must be usable by linguists with relatively little experience of experimental methods, and should follow logically from initial explorations with the software.
3. Methods
We decided at an early stage that the tools we were developing should be consistent as far as possible with the three-level view of the corpus used by ICECUP (sets of queries, sets of cases, single case), and implemented as extensions to ICECUP.
The reasons are user-familiarity, design consistency and integration with corpus exploration. An experimental design editor would be implemented as a new 'overview tool' browsing sets of queries. An experimental sample viewer would view sets of cases and be implemented as an extension to the text browser. The tree viewer would be extended to support the identification of features of a single case. Finally, integrating the software into ICECUP means that one can move between a loose exploration mode and a tighter experimentation mode very easily. See Wallis (2008b; p36) for an illustration.
The new software, ICECUP IV, formalises the experimental process as follows.
- Design. We define a Project as a formal outline of an experiment or series of experiments (i.e., a small research programme). This Project consists of a single case definition and multiple variables. Variables are defined (a) by typological structure and (b) by mapping rules which map elements in the corpus to values. The case definition defines the type of element (a clause, word, construction, etc.) that the experiment is concerned with. It fixes a point (or range) in a corpus tree so that all other grammatical variables are instantiated relative to this point for the case in question.
- Abstraction. This Project is applied to the corpus to abstract an experimental sample (Wallis and Nelson 2001), consisting of cases of the target concept defined by the case definition and the dependent variable (DV). It may then be explored using the sample viewer and tree views. Datapoints in the sample refer to cases in the corpus from which they originate: line for line, case for case. Datapoints are probabilistically weighted by an estimate of their relative independence, i.e. the prior probability that they are independent. See Section 4.5 below.
- Analysis. The sample can then be analysed. Single or multi-variate analysis is performed using a statistically sound knowledge discovery method that explores a space of possible hypotheses connecting independent variables with the DV. The result is a series of independent hypotheses in an integrated panel within the sample viewer.
- Evaluation. Each hypothesis generates a 'coverage map' graphically displaying the distribution of each hypothesis, permitting hypotheses to be related in terms of the cases they explain. Users can select a hypothesis and filter the sample - to identify just the cases covered by the hypothesis, the true positives or the false positives.
Projects consist of:
- A case definition consisting of a single Fuzzy Tree Fragment query.
- A number of variables defined by a mapping rule consisting
of a propositional query expression. There are three basic types
of variables:
- Sentence variables containing sociolinguistic values (etc.). These are defined relative to each text unit and may be discrete or hierarchical.
- Grammatical variables containing FTF queries. These are defined relative to each case (via the case definition) and are similarly structured.
- Grammatical count variables contain an ambiguous FTF that may match the case definition multiple times. The number of subcases is returned.
- Optionally: a subcorpus, random or manual subsample, etc. (not included in current release).
4. Results
We would ask assessors to read the following sections in conjunction with the software and the 'Getting Started' guide.
4.1 Defining the experiment
The Project tool window is shown in Figure 1 below. Variables are selected from the menu bar. The case definition is implemented as a mandatory single-value variable with a mapping rule of a single Fuzzy Tree Fragment (this may be extended). Every element in the corpus matching the focus of this FTF may correspond to a case in the abstract model. Other variables classify, quantify or otherwise relate to, this case (Section 4.3).
Every FTF must have at least one focus node, depicted with a yellow border. The focus, rather than the entire FTF, distinguishes the case, so that each case matches a different point in each sentence tree. An FTF may consist of a single node, multiple nodes with a single node focus or multiple nodes with a series of focus elements. In the example shown, the case is defined as a simple clause that postmodifies a noun phrase (see Wallis 2008b).
- Editing the typology. Discrete grammatical variables consist of a typology, edited in the left hand panel. The typology can be hierarchical. Each term has a unique label, edited in situ. 'Drag and drop' and keystroke commands organise this structure.
- Editing mapping rules. Each distinct value in the variable structure is instantiated by a mapping rule, a logical combination of queries. ICECUP's logical expression editor is embedded in this window and extended to reveal the internal structure of FTFs (Figure 1). FTFs may be imported and edited in the usual ICECUP manner.
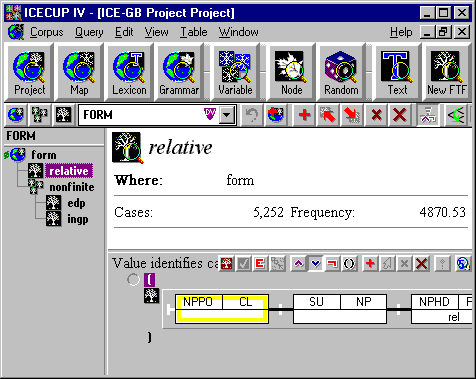
Figure 1. Project tool showing the DV defined as a discrete FTF variable, form ∈ {relative, nonfinite}. The variable typology is on the left, the mapping rule (logical combinations of FTFs) for relative is lower right.
The tool is integrated tightly into the ICECUP platform. Queries can be transferred from exploration to an experiment; the simple search buttons can add queries to the Project, etc. Mapping rules are procedurally evaluated hierarchically, breadth-first (the vertical order in the first panel). Final terms in any value branch may have a 'default' rule (matching all remaining cases) shown as a tick in the hierarchy.
We have also implemented a method for 'refocused evaluation' (Wallis and Nelson 2001). This permits variables to classify values relative to the nearest/furthest term along a particular grammatical axis without requiring relationships to be exactly specified. An example of this might be to classify the host clause of the case (defined as the nearest ancestor) or to identify the most distant adjective in a noun phrase.
Grammatical variables will be used to perform one further process in the final release. It is possible to specify an enumeration field over part of a FTF, e.g. the word(s) under a node. The idea is that when the abstraction process is initiated, discrete variable values (and mapping rules) are created for every distinct pattern found in the corpus. This general technology supports n-grams (Stubbs and Barth 2003) but also many other types of slot-filling operation, integrated into the experimental design. An n-gram may be extracted and employed as part of an experiment.
The platform also supports two additional variable types.
- Sentence variables classify entire sentences (sentences spoken by a female speaker, etc.) and do not require an FTF focus. In addition to manual editing, the user can copy an existing sociolinguistic variable (or parts thereof) into the Project window, and edit the typology and mapping rules (e.g., to import the text category variable and reorganise categories).
- Grammatical count variables are numeric variables defined by a mapping rule consisting of an ambiguous FTF - i.e., an FTF that can match the same part of the tree more than once. The program simply records the number of times that this FTF matches the tree where the focus is identical. This is intuitive and powerful. Users can define variables to count, e.g., the number of words, clauses, etc. below, or in any other position around, the focus point.
An experiment requires a target dependent variable (DV) and a number of independent variables (IVs). Selecting a variable in the Project and hitting Browse opens the query results viewer, revealing the experimental sample case by case.
4.2 Browsing the experimental sample
The second major component of the new software is the sample viewer (Figure 2). A project consisting of a single case definition obtains a query results view for that FTF. Cases are classified by each variable we add. The sample viewer is an integrated extension of the query view, supporting concordancing, revealing levels of annotation, etc.Thus the first extension is to provide a 'spreadsheet' view of the experimental sample alongside each case in the corpus. Each row represents a single case in a sentence. Each column represents a single variable, and multivariate experiments are supported.
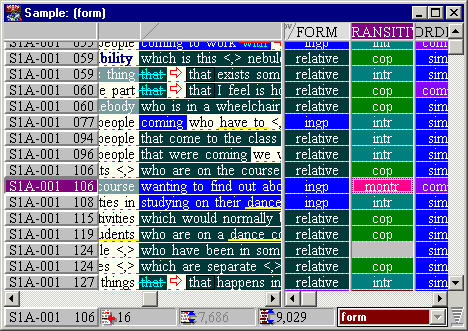
Figure 2. Browsing example cases for form in ICE-GB. ICECUP finds 9,029 cases of either relative or nonfinite postmodifying clauses. The tool unites a corpus concordance (left) with a sample table view (right).
The data is colour-coded for ease of differentiation when 'eyeballing' the data. The interface is extremely tightly integrated. The concordance view and columns scroll sideways separately but scroll vertically together. (Every row represents two views of a case, so these must be aligned.)
Further, each case in the sample is probabilistically weighted according to a case interdependence model (Section 4.5 below). These probabilities may be revealed as a further column on the left of the concordance.
A deep integration with ICECUP means that a spy window can be opened to track the area of each corpus tree surrounding the case (Figure 3) to interrogate a particular grammatical analysis and view the instantiation of variables.
This viewer is scalable to millions of cases. The window loads trees from disk, matches FTFs and displays them as the window is scrolled. In fact, the full experimental model need not be completely abstracted until analysis. Every displayed case is evaluated when required.
ICECUP abstracts the experimental sample as a background process. The case definition and the DV identify a candidate set of text units. With the exception of certain (rather restricted) circumstances where the candidate set reduces to a single pre-indexed query, it is necessary to apply a background proof method which matches the case definition to the sentence, and then
- classify or count every separate case for each variable, and
- compute the relative independence probability weighting.
We discuss these processes in the following sections.
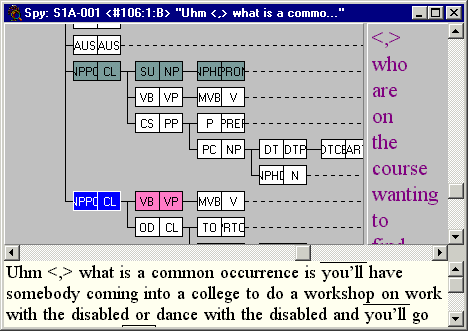
Figure 3. Tree viewer linked to the case browser in Figure 2. This reveals (a) the classification of the selected case by a particular variable, and (b) two matching cases (postmodifying the same noun) in the sentence.
4.3 Classification, unification and proof
The process of matching FTFs to trees is carried out by a robust theorem proof developed under ESRC project R000222598. The current research applies this proof method in novel ways, e.g., where numeric variables count combinations of subcases. In particular, this project implements a logic of cases.
ICECUP 3.0 contained a logic of queries implemented by set intersection, union and negation. This is efficient but does not distinguish between multiple cases in any given sentence. ICECUP 3.1 (Nelson et al. 2002) employed logics of node patterns and textual wild cards. This permitted FTFs to contain nodes such as "not a clause" ('¬CL') or word slots defined by a set.
These applications of logic are limited. The principal expressive weakness of FTFs is common to all model-based representations: they are necessarily conjunctively comp-osed. All atoms must be simultaneously true. Within a single FTF it is not possible to state, e.g. 'find me a structure matching A or B', or 'find me a structure A which does not contain a sub-element B'. The solution requires that A and B share a common focus and are then unified to the same cases (Wallis 2007).
All operations are performed on a finite set of cases specified by the case definition. Mapping rules are optimised by directing the proof method to operate on a set of matching cases. FTFs are matched to each case in this set of cases. Variables are defined for each. Hierarchical classification cascades this, thus a mapping rule for a subvalue v ⊂ V is only applied to cases matching V. See Wallis (2008b: 20).
Count variables operate similarly. They use an ambiguous FTF to return the number of independent matching cases coinciding with the focus.
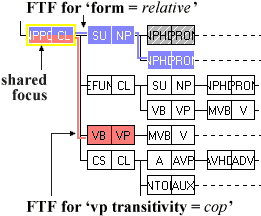
Figure 4. Unification of two FTFs, A and B.
The text browser does not rely on the corpus or dataset to be loaded into memory. It is scalable to search results spanning millions of cases. On the other hand, multi-variate analysis algorithms are computation-ally intensive. They should run on datasets loaded into memory where possible.
The process of extracting this dataset, abstraction, is a background process similar to search. It evaluates each case as a tuple <value1, value2… valuen>, and adds it to an internal model in memory. We use a lossless compression method to store identical tuples once, summing frequencies. This can be very efficient in memory and computation, depending on the level of regularity in the dataset. We also compute frequency totals for each variable and discrete value, and frequency distributions for numerical values.
In the proposal and in recent papers (Wallis 2008c) we have raised the problem of case interaction. Briefly, the issue is that cases in the corpus are not independent as a random sample would require. This presents an experimental platform with a problem, particularly in relation to low frequency linguistic events (and small samples) if there is substantial clustering in a relatively few texts.
The classical experimental solution would be to ensure that only one case is obtained from any subtext in the corpus. However, this is an inefficient use of data and would prevent many specific research questions from being pursued with current corpora. On the other hand, merely because cases appear in the same subtext does not mean that they are entirely dependent on one another. The challenge is to model the relative dependence of cases. Different degrees of case interaction were identified by Nelson et al. (2002: 272) as including:
- overlapping (full and partial);
- embedding (e.g. clauses within clauses);
- coordination, and
- explicit repetition of topics, participants, actions etc.
The causes of case interaction are also worthy of consideration. We can hypothesise about three principal causes:
- language production constraints (attention and memory of speakers);
- speaker/author preferences, and
- the environment and topic of the text.
The task is to model this interaction probabilistically.
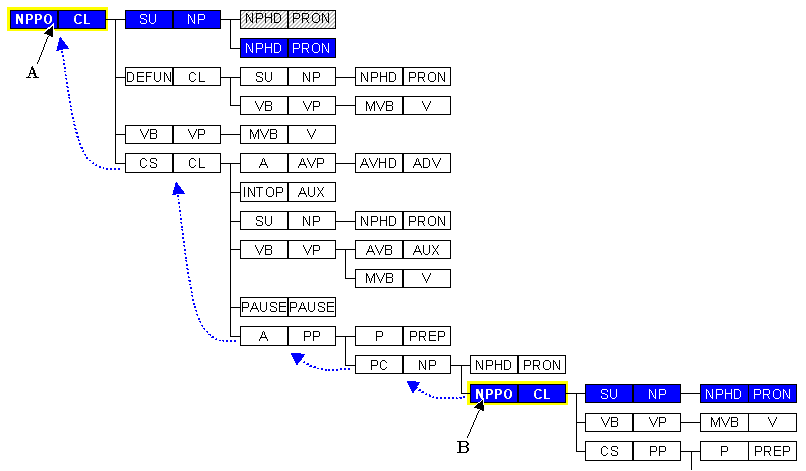
Figure 5. Embedding distance between two cases: three levels between B and A.
The software employs a simple model estimating case independence within a single sentence or text unit. This model assumes that the grammar in the corpus is valid, corresponding to overlapping, embedding and coordination proximity. (It does not consider speaker preference or topic repetition.)
The model attempts to model the interaction between cases in the corpus according to their grammatical proximity within a tree. In Figure 5 the embedding distance between cases A and B is calculated as a measure of the number of intervening clauses and phrases. The assumption is that the greater this distance, the greater the prior likelihood that the two cases are independent from each other.
We can assume that the probability of any given case is between 1 (independent) and 1/n (co-dependent), where n is the number of cases in that text unit. If cases overlap we can only assume that they are co-dependent. We model the fall in interaction (and rise in probability) between two cases as they become more distant along different grammatical axes. For more than two cases in the same sentence we measure the distance to the nearest case to avoid a combinatorial explosion.
The model is defined as follows:
| h x 0.3 | where cases are siblings | h is horizontal distance | ||||||
| k = | v x 0.2 | where cases are embedded | v is embedding distance | |||||
| v x 0.3 | otherwise | v is distance to common ancestor | ||||||
| p = | 1/n ≤ (1+log(k+1))/n ≤ 1. | |||||||
The constants in this expression could be adjusted (we have considered this as a user-option) but nonetheless this model obtains a fairly conservative logarithmic trend. Distance is measured between the focus of each case, as in Figure 5.
It is possible to further complicate this model by including textual-distance measures and considering the interaction of cases in other sentences in the text. However, a priori models of this type have a limited value. If our comments about probable causes of interaction hold, different phenomena are likely to act at a distance to differing degrees.
The mathematical assumptions here make a stronger claim on what we might term the 'empirical validity of the particular grammar' than that generally implied by corpus linguistics. Consideration of a posteriori methods of measuring case interaction leads us to the conclusion that this could be key to the empirical evaluation of (a) grammatical frameworks and (b) language production. See Section 8 below.
4.6 Analysis of the experimental sample
An abstracted sample is analysed using a multi-variate knowledge discovery method. The independent hypothesis algorithm from the co-investigator's UNIT supervised learning tool (Wallis and Nelson 2001) was re-implemented from first principles, optimised and integrated into the architecture.
This algorithm explores the combinatorial space of hypotheses defined by a set of discrete or hierarchical variables, A…Y, to attempt to predict the value of a further variable, Z. Hypotheses take the form 'if A=a and B=b… then Z=z'.
The control algorithm takes the null hypothesis and attempts to improve it by adding a condition consisting of a variable and value 'A=a'. It uses a hierarchical log likelihood statistic to test if the distribution of cases across the dependent variable Z is affected by this precondition. If so, it then computes the optimum outcome for the hypothesis, 'Z=z'. Hypotheses are scored by a composite utility function, the idea being that the 'best' hypotheses are those of the greatest utility.
The algorithm explores the hypothesis space by exhaustive statistically sound hill-climbing on utility. A secondary hypothesis containing two conditions 'A=a and B=b' must have a greater utility than one containing either condition and this difference must be statistically sound. This exhaustive condition is an optimisation from this project.
Utility is computed as follows:
utility = coverage^i x fitness^j x accuracy^k x swing^l.
where coefficients i+j+k+l=1. The factors are probabilistic: coverage is the proportion of cases covered by the hypothesis; fitness is the accuracy of the inverse hypothesis; accuracy is the naïve (simple fraction) or Laplacian accuracy of the hypothesis; and swing is the probabilistic improvement over random chance.
In the current beta release coefficients are set to k=0.8, l=0.1, i=0.07 and j=0.03. This means that utility primarily maximises on accuracy and swing, but all else being equal, hypotheses of high coverage and fitness also benefit. Varying coefficients provide a high degree of tuning and in the final release this will be available as an advanced option. Downplaying accuracy and swing tends to lead to very simple short rules.
A number of other improvements will be implemented in the final release. Currently the algorithm does not analyse numeric count variables although ICECUP can abstract them. In addition we are considering alternative conditions such as 'A ∈ {a1, a2…}' for independent and dependent variables.
The algorithm is applied to the sample defined by the Project. It runs in the background, can be run concurrently with other background processes and can be paused and restarted at any time.
4.7 Evaluation of results
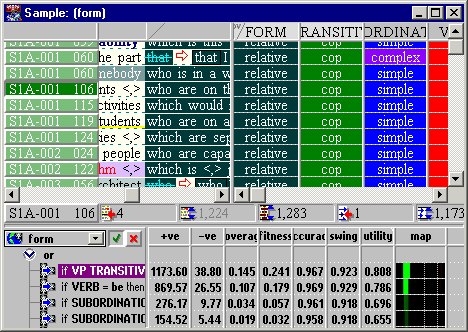
Figure 6. Exploring the results of analysis of the sample in Figure 2. The knowledge discovery algorithm has identified a set of independent hypotheses (lower panel). When a user selects a hypothesis (e.g. if VP transitivity = cop then form =relative) the sample can be filtered by the cases covered (upper). The green 'tick' limits the sample to true positives.
Hypotheses are sent to a hypothesis panel in the sample viewer (Figure 6). Hypotheses are reported with a table of statistics. Users can sort hypotheses by any of the columns, by default, in descending order of utility.
This list may be long - an example with 16 independent variables finds 1,173 different hypotheses (Figure 6) predicting the one variable. Clearly, methods for discriminating between hypotheses are required. However, obtaining multiple explanations for the same phenomenon is often of considerable value. Hypotheses explaining the same cases in the corpus may derive from a common root cause. Two tools for evaluating hypotheses are provided.
The first is the coverage map in the final column of the table. This shows graphically the distribution of the hypothesis over the cases, with green representing the true positives (supporting evidence) and red the false positives (counter evidence). The relationship between copular transitivity and the verb to be is clearly visible in Figure 6. This would allow a linguist to revise their experimental design and eliminate one of these variables or combine them hierarchically as subtypes of cop, i.e., to be vs. not to be.
The second tool works by filtering the sample. Selecting a hypothesis in the hypothesis panel shades the relevant rows and columns. Rows are shaded green for true positives, red for false positives (cases that are not covered remain grey). If the user selects one of the filter buttons at the top of the panel, the sample changes to reflect just these cases. Linguists can, literally at the touch of a button, see the cases covered by a hypothesis. Since this tool is deeply integrated into the platform they can drill down to an individual clause to inspect false positives (say), triggering further revision of their experimental design and bringing the cycle full circle.
5. Activities
The co-investigator presented an outline of the research at the International Computer Archive of Modern and Mediaeval English (ICAME) in Helsinki 2006, demonstrated the mature ICECUP 3.1 at the same conference at a workshop on annotation, and was invited to participate in the plenary session. An early version of ICECUP IV was presented at ICAME 2007 in Starford upon Avon, demonstrating the definition of experiments and the abstraction of a sample.
6. Outputs
6.1 Software
Wallis, S.A. (2008a) ICECUP IV. The ICE Corpus Utility Program for experiments in natural language with parsed corpora. UCL: Survey of English Usage. Download
6.2 Papers delivered, publications, etc
Wallis, S.A. (2006) Experimental corpus linguistics: the next generation? Paper presented at ICAME-27, Helsinki, Finland.
Wallis, S.A. (2006) The Future of Corpora: Tools and Annotation. Plenary paper, ICAME-27, Helsinki, Finland.
Wallis, S.A. (2007) Annotation, Retrieval and Experimentation. In Meurman-Solin, A, and Nurmi, A.A. (ed.) Annotating Variation and Change. Helsinki: Varieng, University of Helsinki. » ePublished
Wallis, S.A. (2008b) Getting Started with ICECUP IV. Experiments in Grammar and Lexis. UCL: Survey of English Usage. » ePublished
Wallis, S.A. (2008c) (in press) Searching treebanks and other structured corpora. Chapter 34 in Lüdeling, A. & Kytö, M. (ed.) Corpus Linguistics: An International Handbook. Handbücher zur Sprache und Kommunikations-wissenschaft series. Berlin: Mouton de Gruyter.
![]()
7. Impacts
The research is at an early stage regarding dissemination. The first expected impact will be on the targeted end users of the platform (and the users of their research). These users are academic linguists (especially corpus linguists), MA and PhD students. A PhD student project might currently involve an experiment of (say) three or four variables on a corpus and discussion of the results. Now, experiments like this can be formulated and carried out extremely quickly with the software. This endorses the statement in our original proposal that carrying out this research would initiate a paradigm shift similar to the impact of effective query systems for parsed corpora.
This platform provides an extensible methodology for evaluating the interaction of linguistic events, currently defined by grammar and lexis. Adding further layers of annotation permits, e.g., the interaction between grammar and semantics to be explored. The requirement is that the query representation must be able to relate elements between levels of annotation (typically, via the sentence; Wallis 2008c).
The third expected impact is likely to take time. This is the impact outside of linguistics of a viable integrated platform of this type. This research has implications for other subfields of knowledge discovery in databases which, like Wallis and Nelson (2001), concern themselves with extracting hypotheses from structured data.
8. Future Research Priorities
We believe that the question of modelling case interaction (see Section 4.5) - and the interaction of grammatical constituents more generally - present new opportunities in grammatical research. Rather than consider particular linguistic interactions where case interaction is a problem to be solved, we wish to consider modelling total interactions and identifying whether derived models are consistent with the grammatical representation.
If an ideal surface grammar represents a generalisation of the unfolding of language structure, then we hypothesise that such a grammar would structurally reflect the statistical evidence for interdependence. From this point of view, deviation from the trend is interesting in and of itself. Systematic deviation points to problems in the representation. Unsystematic deviation may signal local errors in the analysis.
Taken together, ICE-GB and DCPSE contain over one million words of parsed orthographic transcribed speech data, two thirds of which (650,000) are wholly spontaneous. 250,000 words are spoken in potentially rehearsed conditions. This data is a goldmine for psycholinguistics research.
We have identified two sets of research questions.
- The first would collect evidence to build a statistical model of interactions. We could consider the impact of grammatical distance, specific elements (e.g. comment clauses) and transformations (e.g. inversion) on particular phenomena.
- The second concerns whether this method may be used to find empirical evidence for or against a particular grammar.
9. Additional references
Nelson, G., Wallis, S.A., and Aarts, B. (2002) Exploring Natural Language: Working with the British Component of the International Corpus of English, Amsterdam: John Benjamins.
Stubbs, M. and Barth, I. (2003) Using recurrent phrases as text-type discriminators: a quantitative method and some findings. Functions of Language 10, 1: 65-108.
Wallis, S.A. and Nelson, G. (2001) Knowledge discovery in grammatically analysed corpora. Data Mining and Knowledge Discovery, 5: 307-340.
![]()
This page last modified 14 May, 2020 by Survey Web Administrator.