Survey of English Usage
- Home
- About the Survey
- Staff
- Research Projects
- The International Corpus of English (ICE)
- ICE-GB
- DCPSE
- Corpus Queries
- Next Generation Tools
- The English Noun Phrase
- The English Verb Phrase
- Subordination in Spoken & Written English
- Teaching English Grammar in Schools
- Research Resources
- Software Sales
- Mobile Apps
- Events
- Summer School
- Study With Us
- Courses for Teachers
- Survey Archives
- Links
 ICE-GB
ICE-GB
ICE-GB is the British component of the International Corpus of English (ICE).
ICE began in 1990 with the primary aim of providing material for comparative studies of varieties of English throughout the world.
More than twenty centres around the world are preparing corpora of their own national or regional variety of English. These include
| Australia Cameroon Canada East Africa (Kenya, Malawi, Tanzania) Fiji Great Britain (parsed) Hong Kong India Ireland Jamaica Kenya Malta |
Malaysia New Zealand Nigeria Pakistan Philippines Sierra Leone Singapore South Africa Sri Lanka Trinidad and Tobago USA |
ICE-GB was first released in 1998 with ICECUP 3.0. Since then it has been used for research and education in universities, colleges and schools all over the world.
ICE-GB Release 2 on CD-ROM
 |
|
Release 2 is aligned with the 300 audio recordings which are available as an optional extra. You can also upgrade from ICE-GB R1 at a low cost. See the order form for details and why you should consider upgrading below.
ICE-GB contains:
- One million words of spoken and written British English from the 1990s.
- Tagged, parsed and checked.
- Bundled with the ICECUP 3.1 exploration software designed for parsed corpora. This is simply updated to the very latest ICECUP 3.1.1 Windows 64bit-compatible version.
- Supplied with extensive on-line help.
- Option: Audio recordings for 300 spoken texts.
Order ICE-GB Release 2 | Order ICE-GB Release 2 Sound | Download ICE-GB Release 2 Sample and ICECUP 3.1
There are numerous English corpora available.
» Many are available on CD from ICAME (see right).
WHAT IS SPECIAL ABOUT ICE-GB?
ICE-GB is fully grammatically analysed. Like all the ICE corpora, ICE-GB consists of a million words of spoken and written English and adheres to the common corpus design. 200 written and 300 spoken texts make up the million words. Every text is grammatically annotated, permitting complex and detailed searches across the whole corpus.
ICE-GB contains 83,394 parse trees, including 59,640 in the spoken part of the corpus. This is the biggest collection of parsed spoken material anywhere with the exception of DCPSE (which only contains spoken material). The picture below shows ICECUP 3.1 displaying a single tree from the spoken part of the corpus.
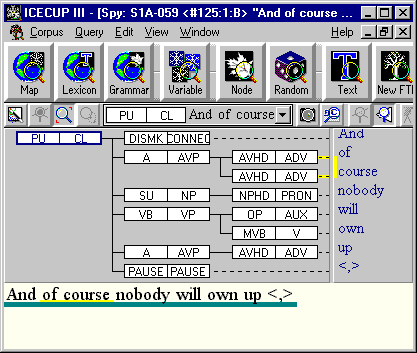
ICE-GB has been fully checked. It was checked by linguists at several stages in its completion, using both a traditional ‘post-checking’ strategy and also by cross-sectional error-based searches. We do not believe that the analysis in the corpus is perfect, but it is not systematically imperfect - unlike the best parser output.
ICE-GB comes complete with ICECUP. ICECUP allows you to perform a variety of different queries, including using the parse analysis in the corpus to construct Fuzzy Tree Fragments to search the corpus.
Release 2 of ICE-GB is now available. This includes, as an optional paid-for extra, the digitised speech recordings of the spoken part of the corpus, aligned with the text. This allows researchers to play back the original source of the text that they can see on their screen.
A sample corpus from ICE-GB Release 2 and ICECUP 3.1 is now available for download. We also invite linguists to contribute to the development of cutting-edge corpus linguistics tools by participating in our beta programme.
A book about ICE-GB and ICECUP was published in 2002.
More information about ICE-GB
![]() Comparing ICE-GB with DCPSE and other similar treebanks
Comparing ICE-GB with DCPSE and other similar treebanks
![]() ICE-GB corpus design
ICE-GB corpus design
WHY SHOULD I UPGRADE FROM RELEASE 1?
ICE-GB Release 1 was a milestone in corpus linguistics when it was released in 1998. Why should any current user of ICE-GB consider upgrading to Release 2? Here are three reasons.
- An enhanced corpus. We have reinstated some missing material and corrected the transcription (and thus the parse analysis) when we reviewed the recordings.
- More facilities. ICECUP 3.1 contains many more facilities for search and exploration. These include lexical wild-card queries, enhanced FTFs, an integrated lexicon and grammaticon for ICE-GB and the ability to compute and extract statistical tables.
- Synchronous audio. If you want to play the audio aligned with the transcription you will need to upgrade. This facility means that if you search for a word in the corpus, you can hear the passage containing that word.
See also:
The ICE project is internationally coordinated by Dr Gerald Nelson at the Chinese University of Hong Kong. He can be contacted at gnelson@arts.cuhk.edu.hk.
The ICE-GB project is coordinated by the Survey of English Usage. Enquiries should be sent to the Survey (ucleseu@ucl.ac.uk).
This page last modified 14 May, 2020 by Survey Web Administrator.