Survey of English Usage
- Home
- About the Survey
- Staff
- Research Projects
- The International Corpus of English (ICE)
- ICE-GB
- DCPSE
- Corpus Queries
- Next Generation Tools
- The English Noun Phrase
- The English Verb Phrase
- Subordination in Spoken & Written English
- Teaching English Grammar in Schools
- Research Resources
- Software Sales
- Mobile Apps
- Events
- Summer School
- Study With Us
- Courses for Teachers
- Survey Archives
- Links
ICE-GB Corpus Design
ICE-GB contains 500 texts of approximately 2,000 words each. Many of these texts are composite, that is, they consist of two or more different samples of the same type which have been combined to make up a 2,000-word 'text'. In the category of business letters, for instance, a total of 198 individual letters have been included. We refer to these individual samples as 'subtexts'.
The table below provides a summary of the composition of the ICE-GB corpus.
|
||||||||||||||||||||||||||||||||||||||||||||||||
| ICE-GB Summary statistics | ||||||||||||||||||||||||||||||||||||||||||||||||
With just over one million words, ICE-GB is small in comparison with the British National Corpus (BNC). The BNC contains 100 million words, and samples British English from approximately the same period.
However, ICE-GB was designed primarily as a resource for syntactic studies, not for lexical studies. Unlike the BNC, every text unit ('sentence') in ICE-GB has been syntactically parsed at function and category level, and each unit is presented in the form of a syntactic tree. The 83,394 trees in the corpus represent an invaluable resource for studies of the syntax of contemporary British English.
Corpus structure
The sampling structure of the corpus is shown below.
|
|||||||||||||||||||||||||||||||||||
| ICE Corpus Design | |||||||||||||||||||||||||||||||||||
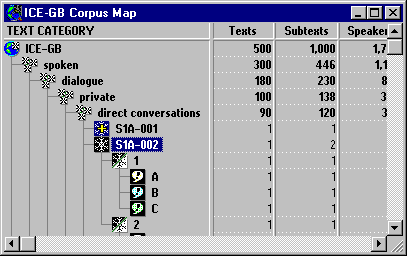
This structure is reflected in the TEXT CATEGORY variable in ICECUP. The following diagram shows ICECUP's Corpus Map with the entire corpus - at the top left - then spoken, dialogue, private, direct conversations down to the first text S1A-001, S1A-002, etc. S1A-002 is opened further showing subtexts and speakers.
The texts in ICE-GB date from 1990 to 1993 inclusive. This means that the printed texts were originally published, and the spoken texts originally recorded, during this period. The corpus does not include reprints, second or later editions, or transcripts of repeat broadcasts. For handwritten material, such as letters and essays, these dates refer to the date of composition.
All authors and speakers are British. This means that they were born in Great Britain, that is, England, Scotland, or Wales. In a small number of cases, we have relaxed this criterion to include those who were born elsewhere, but moved to Britain at an early age.
See also:
![]() Comparing ICE-GB with other treebanks
Comparing ICE-GB with other treebanks
This page last modified 14 May, 2020 by Survey Web Administrator.