Survey of English Usage
- Home
- About the Survey
- Staff
- Research Projects
- The International Corpus of English (ICE)
- ICE-GB
- DCPSE
- Corpus Queries
- Next Generation Tools
- The English Noun Phrase
- The English Verb Phrase
- Subordination in Spoken & Written English
- Teaching English Grammar in Schools
- Research Resources
- Software Sales
- Mobile Apps
- Events
- Summer School
- Study With Us
- Courses for Teachers
- Survey Archives
- Links
 Next Generation Tools
Next Generation Tools
Next generation tools for linguistic research in grammatical treebanks
funded by

Download β
version of ICECUP IV
Final Report
New: Referees' Comments
Ref: R 000 23 1286
Institution: University College London
Department: Department of English (Survey of English Usage)
Principal investigators: Bas
Aarts and Sean Wallis
Period: 1 January 2006 to 31 December 2007
"Dissection is the mother of Anatomy"
Aims and objectives
This project will develop a computer program for linguists to carry out complex, statistically sound experiments on a large, grammatically analysed corpus (treebank). At present this is time consuming, error prone and difficult, and only simple experiments are feasible.
The proposal is to implement the entire experimental cycle (definition, sampling, analysis and evaluation) in software.
This has three immediate benefits:
- Previously difficult tasks become automatic.
- New procedures - including automatic enumeration of discrete and numeric variables, evaluation of case interaction, and the analysis of several variables in combination - become possible.
- Linguists can comprehend their results by reference to cases in the corpus.
The project builds upon our existing state-of-art corpora and software, and the linguist user-community.
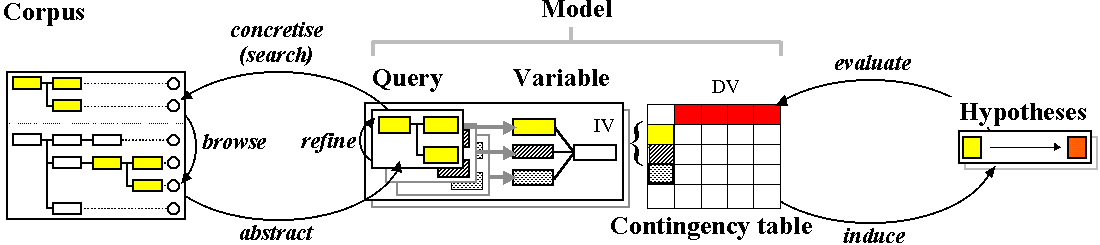
Figure: a simple type of experimental cycle
(click on image to magnify)
Specific aims
- To develop a experimental research platform in corpus linguistics
capable of supporting a research cycle, in the form of a series
of complex related experiments, within a single piece of software.
This platform will be constructed as a series of extensions to
the existing ICECUP
platform, utilising the grammatically parsed corpora ICE-GB
and DCPSE and building on the
experience of our existing user base.
- To develop and refine a number of software tools and algorithms
within this context.
Tools will include
- a tool for defining, elaborating and evaluating lexical-grammatical variables,
- a ‘spreadsheet’ dataset sample viewer (defined by an experimental design), and
- a tool for visualising the results of analysis.
Automatic algorithms will
- generalise variables from the corpus,
- abstract corpus samples, and
- statistically analyse the results.
These tools will be integrated into the current software platform to exploit existing syntheses and firmly establish a cycle of rapid experimentation on a parsed corpus.
- To develop documentation, tutorial material and ‘wizards’ to aid the construction of statistically sound and linguistically meaningful experiments.
Non-technical summary
The research is to develop, in conjunction with an existing community of researchers, a software environment for carrying out experimental research in corpus linguistics, with a particular emphasis on parsed text corpora. Corpora are collections of (transcribed) spoken and written passages, annotated in a number of different ways. A parsed corpus is one where the grammatical structure of each sentence is included. As corpora grow in size and complexity (typical parsed corpora are around the 1 million word mark), corpus linguistics research becomes increasingly dependent on computer software support.
Previous research focused on developing an effective, linguistically meaningful, grammatical query system. This transformed possibilities in corpus linguistics. Searches which had previously taken weeks could be performed in seconds. And simple experiments could be constructed around these queries, results being analysed manually. Where a previous generation of researchers had focused on studies of distributions and difference between samples, or used a corpus as a starting point for philosophical discussions of language, the parsed ICE-GB corpus and its accompanying software, released in 1998, can be used to investigate how one aspect of a linguistic choice can affect another.
While the range of potential research possibilities continues to expand, using current software, experiments require careful planning, are difficult, time consuming and prone to error. There is no easy fit between directed searches and enumerative approaches to research (collocations and n-grams). And the separation of statistical analysis from the corpus means that it is difficult to work out how alternative hypotheses interact.
In this proposal we describe how the existing exploration platform may be extended into one supporting the entire experimental cycle:
- defining the structure of an experiment and its variables,
- extracting a sample from the corpus,
- carrying out an appropriate statistical analysis on this sample, and
- evaluating the results with respect to the original corpus from which they are obtained.
Supporting this formal approach - which presumes that the researcher knows precisely how to express what s/he is looking for in advance - are algorithms which define variables from actually existing variation in the corpus. One can define discrete variables by underspecifying a query and asking the software to list the alternatives that exist in the corpus. A similar approach elaborates numeric (integer) variables.
Once data has been collected the platform will support a variety of statistical and computational methods for analysis. The structure of chosen variables (discrete, hierarchical, ordinal) specifies the statistical test to be used. We will also provide algorithms which look at more than one predictor variable at a time and search for combinations of variables which most cogently predict the target linguistic event. Researchers will then be able to consider alternative hypotheses.
A researcher faced with alternative explanations of the same phenomenon will wish to know just how independent one hypothesis is from another. We will provide analysis visualisation tools to identify how cases justifying particular hypotheses overlap, and identify these cases in the corpus. Evaluation of results is then by reference to wider linguistic interpretations and with respect to original sentences.
The approach is highly general and extensible. We use the medium of grammatical investigations into parsed corpora for reasons of access (both to data and a community of active researchers) and because in this field there is a substantial existing literature for comparison. The addition of further levels of annotation in corpora offer the promise of future work in constructing theories that relate these levels to grammar. In this project the crucial question is to ensure that the approach is valid and usable by linguists.
NB. An extended discussion of the relationship between exploration, experimentation and discovery is covered in the Methodology pages on our website.
Potential impacts of the research
- It will firmly establish sound experimental standards in linguistic methodology.
- It will make complex experiments in linguistics viable and readily reproducible (a paradigm shift analogous to the impact of the development of an efficient and usable grammatical query system).
Relationship with other CL methodologies
Engaging in scientific experimentation is daunting and off-putting for many linguists. In the past, scientific procedures were difficult to apply to language data, because datasets were insufficient, or, owing to limited annotation, testable hypotheses were too specific to have theoretical impact.
As a result, corpus linguistics has tended to concentrate on:
- Distributional differences between texts, where research questions focus on contrasts between subcorpora: such as across genres, authors, varieties, and periods (Oakes 1998).
- Identifying lexical collocates, detecting repeated patterns of association (Oakes 1998) including automated methods such as n-gram extraction (Stubbs and Barth 2003).
- Exemplification of grammatical themes, where the corpus is treated as a source of sentences for the purpose of exemplification (Sinclair et al 1987; Greenbaum 1996).
- Algorithmic generalisation for natural language processing programs, where results are ultimately evaluated by performance rather than linguistic insight (Briscoe 1996).
Each of these approaches has a different research goal (identifying linguistic contrasts; identifying idiomatic lexical patterns and small clauses; justification of grammatical theory; developing a viable algorithm).
This project has a different research goal – evaluating the grammar of naturally occurring speech and writing.
User engagement and communication plans
The main immediate beneficiaries of this research will be linguists who are interested in researching the syntax of the English language. Longer term impacts are expected on the field as a whole, in other languages and with other levels of annotation. The approach taken here is extensible, for example, to contrast alternative parsing schemes or to evaluate the interaction between grammar, morphology and lexis.
We currently publish and distribute ICE-GB with the ICECUP software by selling copies of the CD-ROM to institutions and individuals. A sample corpus of 20,000 words, plus software, is available free from the Survey website (www.ucl.ac.uk/english-usage). ICECUP 3.1, an evolutionary advance on the 1998 edition, is published this year (at time of writing it is in beta from our website). This 3.1 release is directed at extending query expressivity (wild cards and logic) and providing new tools (a lexicon and grammaticon), aiming to bridge the gap between more traditional lexically focused research and new possibilities in grammatical studies.
We will disseminate the proposed software in a similar way, at cost and over the internet. However supplying novel software necessarily requires significant post-release support and engagement. Following publication we will organise a workshop on experimental methods in corpus linguistics and publish further supporting materials via our website.
A reference book on ICE-GB, entitled Exploring Natural Language: Working with the British Component of the International Corpus of English (Nelson, Wallis and Aarts 2002), was published by John Benjamins. This contains a dedicated chapter on research methods in parsed corpora. As members of the corpus linguistics community, and publishers of the corpus and software, we have a continuous engagement on this topic.
This proposal is the result of this process. We have carried out a number of pilot experiments for this project, notably Wallis and Nelson (2001), which demonstrated the viability of the core approach and many of the proposed algorithms. Extensions to that approach, including the extraction of numeric variables (Ozón 2004) and the enumeration of variables from the corpus, are prompted by suggestions and requests from linguists at conferences. We have generalised from a number of existing methods in corpus linguistics. Future extensions to the platform will be possible. The principal criterion for a tool’s inclusion is that the tool must have a clear and consistent function in the context of the platform, supporting the experimental cycle, rather than simply provide an interesting diversion. In particular, any future analytical tools will cross-reference the corpus, so that abstract generalisations obtained by computation may be made concrete and understood.
There are two further sets of beneficiaries. Secondary beneficiaries are the users of linguistics research, including language teachers, ELT, etc. Finally, this project breaks some new ground in ‘assisted computation’ approaches to research in other complex datasets analogous to treebanks. There are applications for this methodological approach beyond the world of linguistics.
References
Briscoe, T. (1996). Robust Parsing. In: R.A. Cole, J. Mariani, H. Uszkoreit, A. Zaenen, V. Zoe (eds.). Survey of The State of the Art in Human Language Technology. » e-paper.
Greenbaum, S. (1996). The Oxford English Grammar. Oxford: OUP.
Nelson, G., Wallis, S.A. and Aarts, B. (2002). Exploring Natural Language: Working with the British Component of the International Corpus of English, (Varieties of English around the World series), Amsterdam: Benjamins.
Oakes, M.P. (1998). Statistics for Corpus Linguistics. Edinburgh: EUP.
Ozón, G. (2004). Ditransitive alternation: A weighty account? A corpus-based study using ICECUP. Presentation at ICAME 2004, Verona, 19-23 May 2004.
Stubbs, M. and Barth, I. (2003). Using recurrent phrases as text-type discriminators: a quantitative method and some findings. Functions of Language 10:1. 65-108.
Sinclair, J., Fox, G., Moon, R., and Stock, P. (1987) (eds.) The Collins Cobuild English Language Dictionary. London: Collins.
Wallis, S.A. and Nelson, G. (2001). Knowledge discovery in grammatically analysed corpora. Data Mining and Knowledge Discovery 5:4, 305-336.
This page last modified 14 May, 2020 by Survey Web Administrator.