Survey of English Usage
- Home
- About the Survey
- Staff
- Research Projects
- The International Corpus of English (ICE)
- ICE-GB
- DCPSE
- Corpus Queries
- Next Generation Tools
- The English Noun Phrase
- The English Verb Phrase
- Subordination in Spoken & Written English
- Teaching English Grammar in Schools
- Research Resources
- Software Sales
- Mobile Apps
- Events
- Summer School
- Study With Us
- Courses for Teachers
- Survey Archives
- Links
- DCPSE
- Corpus Design
- DCPSE vs. other treebanks
- Full project description
- ESRC Award Details
- Referees' comments
- Download data
- All (254KB)
- ADJ (31KB)
- ADV (11KB)
- ART (1KB)
- AUX (5KB)
- CLEFTIT (1KB)
- CONJUNC (2KB)
- CONNEC (2KB)
- EXTHERE (1KB)
- FRM (2KB)
- GENM (1KB)
- INTERJEC (2KB)
- N (121KB)
- NADJ (3KB)
- NUM (3KB)
- PAUSE (1KB)
- PREP (3KB)
- PROFM (1KB)
- PRON (4KB)
- PRTCL (1KB)
- REACT (1KB)
- UNTAG (5KB)
- ? (1KB)
- V (53KB)
- Sample corpus
- Order DCPSE
The DCPSE Research Project
Creating a parsed and searchable diachronic corpus of present-day spoken English
funded by

Download data
The complete DCPSE corpus is available on CD-ROM from the Survey of English Usage. DCPSE contains one million words of English sampled across the decades.
You can download raw lexicon data from the links on the right hand side.
Each zip archive contains a text file in the form of a "tabbed table". In ICECUP 3.1, a snapshot of the lexicon looks like the following.
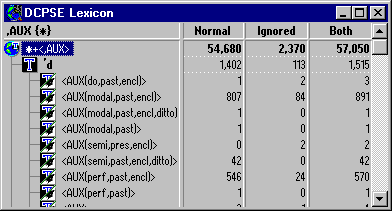
When the lexicon is saved to a text file, one option (Table) outputs a text file containing frequencies separated by tabs, like this:
Normal
*+<,AUX>
etc.
You can import files like this into Excel or any other spreadsheet. If you import the file into a wordprocessor you may wish to convert this section to a table and reformat as appropriate.
Normal Ignored Both *+<,AUX> 54,680 2,370 57,050 'd 1,402 113 1,515 <AUX(do,past,encl)> 1 2 3 <AUX(modal,past,encl)> 807 84 891 <AUX(modal,past,encl,ditto)> 1 0 1 <AUX(modal,past)> 1 0 1 <AUX(semi,pres,encl)> 0 2 2 <AUX(semi,past,encl)> 42 0 42 <AUX(perf,past,encl)> 546 24 570 <AUX(perf,past)> 1 0 1 <AUX> 3 1 4 'll 1,424 113 1,537 ... etc
Note that initial spaces are used to illuminate the structure.
Frequencies cited represent the total number of cases for the lexeme across the entire corpus: some 927,545 words (965,673 including ignored material). "Ignored" refers to words in the corpus where the speaker corrected themselves or where the words were corrected by the editor (rare in the case of DCPSE).
Frequency data includes counts for compounded items. These are listed with the pseudo-frequency 'ditto' so they may be removed or collapsed.
For more information...
For a thorough description and examples of all these part of speech terms in context, we recommend that you download the sample corpus package. This includes the full ICECUP help file including the ICE grammar reference, and of course, sample corpus and software.
A summary of the ICE grammar is published here.
This page last modified 14 May, 2020 by Survey Web Administrator.