Survey of English Usage
- Home
- About the Survey
- Staff
- Research Projects
- The International Corpus of English (ICE)
- ICE-GB
- DCPSE
- Corpus Queries
- Next Generation Tools
- The English Noun Phrase
- The English Verb Phrase
- Subordination in Spoken & Written English
- Teaching English Grammar in Schools
- Research Resources
- Software Sales
- Mobile Apps
- Events
- Summer School
- Study With Us
- Courses for Teachers
- Survey Archives
- Links
The DCPSE Research Project
Creating a parsed and searchable diachronic corpus of present-day spoken English
funded by

Reference: R 000 239 643
Institution: University College London
Department: Department of English (Survey of English Usage)
Principal Investigator: Professor
Bas Aarts
Senior Research Fellow: Sean
Wallis
Research Assistants: Dr Dirk Bury, Lesley Kirk, Yordanka
Kostadinova-Kavalova, Dr Ann Law, Gabriel Ozón
Period: 1 August 2002 to 31 August 2004 (extended by 1 month)
Resources and software for
download
Data for download
Final report
(PDF)
This project was rated Outstanding by the ESRC. Referees'
comments
DCPSE has now been released. You can order the corpus by clicking here.
Introduction
At the core of this proposal are two corpora of Modern British English, both founded at the Survey of English Usage (SEU) at University College London: the London-Lund Corpus (LLC), compiled in the 1960s, and the British Component of the International Corpus of English (ICE-GB), compiled in the 1990s. The project aims to construct a fully parsed and searchable diachronic corpus of spontaneous spoken English, containing carefully selected and directly comparable texts from the LLC and ICE-GB corpora. As will be discussed in the section on Aims and Objectives below, there is a new research impetus in linguistics which concerns itself with recent changes in lexis and grammar. This corpus will be a unique resource for linguists studying the spoken English of a period spanning 25-30 years. There is currently no comparable resource available, and the corpus will be the first of its kind enabling research into current change in spoken language.
The existing corpora
The London-Lund Corpus is the spoken part of the Survey of English Usage Corpus, founded by Randolph Quirk. It contains 510,576 words of 1960s spoken English. The corpus is divided into ‘texts’ of 5,000 words each which were transcribed and prosodically annotated (incorporating tone units, onsets, stresses etc.). Thirty-four were published in Quirk and Svartvik (1980). The corpus was computerised by Jan Svartvik (Svartvik 1990). Many scholars have used the LLC for their research, resulting in hundreds of publications, principal among them Quirk et al. (1972, 1985). It is still one of the largest and most widely used corpora of spoken English, not least because it is the only English corpus that is prosodically annotated. Kennedy (1998: 32) stresses the importance of the LLC in its own right for the study of spoken British English, but also as “a very important baseline record of data…by which other corpora of spoken English can be evaluated… [The texts] have been used by researchers in many countries for studies which go well beyond the study of phonology. The detailed annotation has also facilitated numerous studies of lexis, grammar and especially discourse structure and function”. The SEU has recently enhanced the corpus by adding wordclass tags to it, using the ICE-GB scheme. In addition, the SEU is digitising the original sound recordings which will be supplied – for the first time in the LLC’s history – with the proposed new resource.
ICE-GB is composed of spoken and written texts, distributed over thirty-two text categories. The material dates from the early 1990s. The corpus contains textual markup, wordclass tags, and – unusually – it is one of the few corpora that have been fully grammatically annotated (tagged and parsed): all the sentences/utterances in the corpus have been assigned a tree structure, like the one shown in Figure 1 below:
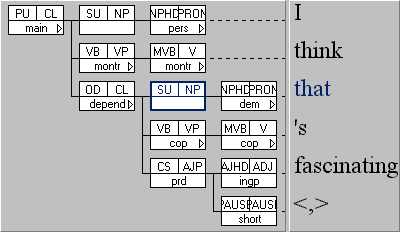
Figure 1: A tree diagram from the ICE-GB corpus.
The annotation has been thoroughly and extensively checked by linguists. ICE-GB incorporates the largest collection of fully parsed and checked spoken British English anywhere. Recently the sound files have become available, and these will be supplied in the new corpus package.
ICE-GB can be exploited with dedicated research tools, such as the innovative ICECUP software, developed at the SEU, with which linguists can search for grammatical constructions. This software is currently distributed with the ICE-GB corpus and over the web (together with a sample corpus). It runs over a network or on stand-alone PCs. At the heart of ICECUP is the Fuzzy Tree Fragments (FTFs) facility which enables users to construct approximate (hence ‘fuzzy’) models of tree structures, which the computer can search for in the corpus. Figure 2 shows an example of an FTF which matches all instances of a verb phrase (VP) followed by a direct object (OD).
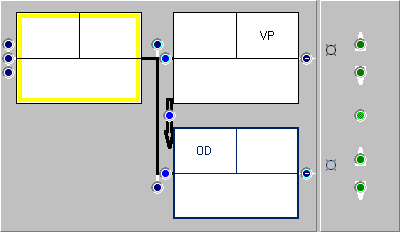
Figure 2: A simple FTF created with ICECUP
The software employs an interface that encourages users to refine their queries through a process of interactive experimentation to explore research questions and to learn the underlying grammar. For more details on ICE-GB, see Greenbaum (1996), Aarts, Nelson and Wallis (1998) and Nelson, Wallis and Aarts (in press). The latter is a handbook for using ICE-GB and ICECUP.
Aims and objectives
Traditionally a distinction is made between diachronic and synchronic approaches to linguistics. The first considers language as it develops through time, whereas the latter takes a ‘snapshot’ look at languages viewed from the present. This old Saussurean dichotomy has recently been called into question, and some linguists have argued that the distinction is an artificial one. These linguists would argue that languages change all the time, even within the synchronic phases. As a result of these new attitudes to language development there is a new research impetus in linguistics which concerns itself with recent change (see Mair 1995, 1997; Mair and Hundt 1995, 1997, Denison 1998, Leech 2000, Smith and Leech 2001).
For linguists who are interested in recent change corpora are especially valuable for data-gathering. At present they will need two separate corpora from two different periods. Naturally, these corpora must be comparable as regards their internal composition (i.e. sampling criteria). An example of work done in this area is Aarts and Aarts (forthcoming) which investigates the use of the English relative pronoun whom. In order to compare data from two periods of Present-Day English (PDE) the authors looked at material from the LLC and ICE-GB. They found that the overall use of whom as a Direct Object has become 90% less frequent over thirty years. Although ICE-GB is grammatically annotated and fully searchable, manual counts had to be carried out to find data in the older corpus. Thus, while the corpora were indispensable tools for this study, the research phase still required the careful pre-selection of comparable texts and manual searching of the LLC. A parsed LLC is essential to permit the systematic exploration of grammatical variation over time, and will greatly facilitate research of this type, especially if it involves complex grammatical patterns.
In order to support research into current change Professor Christian Mair at the University of Freiburg has constructed two corpora of 1990s English: FLOB (Freiburg-Lancaster-Oslo-Bergen) and FROWN (Freiburg-Brown). These corpora are intended to match the LOB (Lancaster-Oslo-Bergen) and Brown corpora containing written English from the 1960s. These are excellent resources enabling linguists to research changes in written English over 30 years. Manual searches are still unavoidable, however, as these corpora have not been parsed. We would like to take Mair’s initiative further. We propose to construct a corpus of British English comprising selections of spontaneous spoken English from the LLC and from ICE-GB. The new corpus will provide linguists interested in recent changes in English with a new and innovative database containing spoken English covering a period of 25-30 years.
We opt for a corpus of spoken English because it is generally recognised that spoken language is primary and the first locus of changes in lexis and grammar.
The resulting resource, which we will call a Diachronic Corpus of Present-Day Spoken English (DCPSE) will allow researchers to investigate changes in the grammar and usage of PDE over a period of 30 years. DCPSE differs from FLOB and FROWN in a number of important ways. Firstly, the corpus will be unique in containing exclusively spontaneous spoken English. We will provide a playback facility enabling linguists to listen to the original recordings. Secondly, the corpus will be parsed which will permit research into synchronic and diachronic grammatical variation. Thirdly, the corpus will be fully searchable using the ICECUP software that we developed for ICE-GB. This software will be modified to operate on the new data. We envisage that DCPSE will be a major new resource complementing the Freiburg corpora, allowing access for the first time to recordings that could hitherto only be listened to at the Survey premises.
The project has the following aims:
- Select a total of 800,000 words of spoken English from comparable categories in the LLC and in ICE-GB (400,000 words from each corpus). The design of these corpora is similar, and it will thus be possible to select identical categories of spoken English. In each case we will select a matching pair of texts, and cross-check the structural markup and tagging in the LLC. Texts will be selected by Bas Aarts. They include face-to-face conversations, telephone conversations, radio discussions, class discussions, parliamentary debates, legal cross examinations, business transactions, spontaneous speeches and interviews. It is important to stress that given the way changes in English propagate themselves we will only select categories of spontaneous English. We will thus exclude prepared monologues, broadcast news etc.
- Integrate the LLC and ICE-GB material.· Modify ICECUP to handle the combined data. ICECUP was originally developed to operate on ICE-GB. It will need to be modified to handle the proposed ‘two-in-one’ corpus.
- Parse the LLC material. Given the ‘messy’ nature of spoken English this will be a major task which is described in detail in the Technical Appendix.
- Ensure ‘analytic consistency’ across the two subcorpora, i.e. make sure that analytical decisions for the LLC material are consistent with those made for ICE-GB. This will necessitate the writing of additional software.
- Manually check the parse results.
- Prepare and enhance the digitised LLC sound recordings, so that these can be used by researchers. The LLC recordings have not been disseminated until now. Randolph Quirk has suggested that we ‘bleep out’ the names in the sound recordings.
- Write documentation and disseminate the new fully searchable diachronic corpus with the ICECUP software.
Methodology
The LLC material will be automatically parsed using the TOSCA parser developed at the University of Nijmegen in the Netherlands. This process is not error-free, and requires significant manual intervention. For this we will implement cross-sectional correction (Wallis, 1999), a process which employs ICECUP to correct patterns of errors globally. This is more efficient and consistent than conventional sentence-by-sentence checking.
Outcome
An 800,000 word corpus of spontaneous spoken British English containing equal amounts of directly comparable material from 1960-1976 and from the early 1990s. The corpus will be textually annotated (marking sentence boundaries, speakers, overlaps etc.), as well as grammatically annotated (tagged and parsed), indexed, and fully searchable with ICECUP, using Fuzzy Tree Fragments and other query systems. The new resource will also feature a lexicon (a database of word-tag combinations in the corpus) and a grammaticon (a database of node combinations). These will enable users to contrast lexical and grammatical distributions in the LLC and ICE.
The proposed resource will be an invaluable research tool for linguists interested in present-day English grammar, as well as for those interested in current changes in this domain. We will describe the new corpus in articles and conference presentations, and we will write a manual (incorporating a tutorial) for the new package, explaining the annotation, the FTF facility and the user interface.
Dissemination
The new corpus, including the digitised sound recordings, will be disseminated on CD-ROM as an electronic database with software. A free download of the software with a sample corpus and documentation will be available over the internet from a dedicated web site. (You can download the ICE-GB sample corpus from here.)
The corpus and recordings will be deposited with the Oxford Text Archive within three months of the end of the project.
Staff
- Sean Wallis, Senior Research Fellow at the SEU, will perform all programming tasks and manage the computational aspects of the project. He will write documentation to accompany the resource.
- Two Research Assistants will be responsible for checking and correcting the grammatical annotation in the corpus. In addition, the RAs will assist Wallis in writing documentation for the corpus.
- Dr. Bas Aarts will supervise the project.
References
AARTS, B., NELSON, G., and WALLIS, S.A. (1998) Using Fuzzy Tree Fragments to Explore English Grammar. English Today 14, 52-56.
AARTS, F. and B. AARTS (forthcoming) Relative Whom: a ‘Mischief Maker’. In: A Fischer and G. Tottie (eds.). Text Types and Corpora.
DENISON, D. (1998) Syntax. In: S. Romaine (ed.). The Cambridge History of the English Language. IV: 1776-1997. Cambridge. 92-329.
KENNEDY, G. (1998) An Introduction to Corpus Linguistics. London.
LEECH, G. (2000) Diachronic linguistics across a generation gap: from the 1960s to the 1990s. Paper read at the symposium Grammar and Lexis. University College London Institute of English Studies.
LJUNG, M. (1997)(ed.) Corpus-Based Studies in English. Amsterdam.
MAIR, C. (1995) Changing Patterns of Complementation and Concomitant Grammaticalisation of the Verb help in Present-Day English. In: B. Aarts, and C.F Meyer (eds.). The Verb in Contemporary English, Cambridge. 258-272.
MAIR, C. (1997) Parallel Corpora: a Real-Time Approach to the Study of Language Change in Progress. In: M. Ljung, M. (ed.). 195-209.
MAIR, C. and HUNDT, M. (1995) Why is the Progressive Becoming More Frequent in English? A Corpus-Based Investigation of Language Change in Progress. Zeitschrift für Anglistik und Amerikanistik 43.2. 111-122.
MAIR, C. and M. HUNDT (1997) The Corpus-Based Approach to Language Change in Progress. In: U. Böker and H. Sauer, H. (eds.). Anglistentag 1996. Dresden. 71-82.
NELSON, G., WALLIS, S.A., and AARTS, B. (in press). Exploring Natural Language. Amsterdam.
QUIRK, R., GREENBAUM, S., LEECH G., and SVARTVIK, J. 1972. A Grammar of Contemporary English. London.
———— 1985. A Comprehensive Grammar of the English Language. London.
SMITH, N. AND G. LEECH (2001) Grammatical change in recent written English, based on the FLOB and LOB corpora. Paper read at the ICAME conference. Louvain-la-Neuve, Belgium.
SVARTVIK, J. 1990 (ed.). The London-Lund Corpus of Spoken English: Description and Research. Lund Studies in English 82. Lund.
SVARTVIK, J., and QUIRK, R. 1980. A Corpus of English Conversation. Lund.
WALLIS, S. (1999) Completing parsed corpora: from correction to evolution. In: A. Abeillé (ed.). Journées ATALA sur les Corpus Annotés pour la Syntaxe – Treebanks Workshop. 7-12.
This page last modified 14 May, 2020 by Survey Web Administrator.