Abstracting and browsing a sample
Once you’ve defined an experiment, you then need some data. You can ask ICECUP to extract a sample dataset from the corpus. This process, called abstraction, applies the definitions to the corpus that you wrote in the Project window.
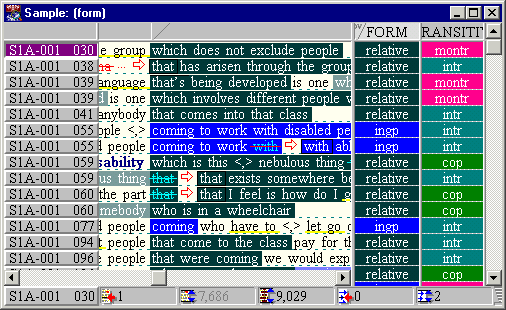
Browsing the variable form tells ICECUP to make form the dependent variable and thus extracts a list of cases matching values of form. These are classified and coloured as shown in the left hand part of the sample browser below.
Note that the left hand side of the view is a conventional concordance view. ICECUP IV is built on top of the ICECUP 3.1 architecture. It has exactly the same tools and commands for exploring the sample as ICECUP 3.1 for exploring the results of a query. For example, you can perform grammatical concordancing, show speaker turns and reveal more sentence context.
The browser has gained a table: two further columns and a header row on the right. These may be hidden if you wish.
In our experiment, we defined two variables, and so we gain two columns. The second variable, vp transitivity, locates the transitivity feature (copular, intransitive, monotransitive, etc.) from the verb phrase within the clause and classifies each case by this value.
Since cases are defined by FTFs, they may be found in different sentences or more than once in the same sentence. Inspecting sentence S1A-001 #106 in ICE-GB, we find the following. Here we selected the pink ‘montr’ cell in the table, so, as well as showing matching cases, the tree highlights that value.
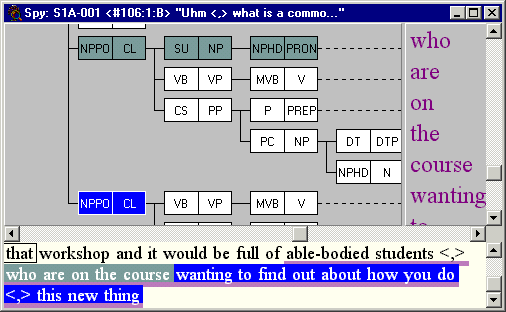
By inspecting the tree we can see that both cases postmodify the same noun (students) and how each clause is realised.
Addressing case interaction
Statistical analysis is conventionally carried out on a random sample drawn from the population that you wish to generalise about. There are two aspects of this.
- Representativeness. In this case, we want to make claims about English language sentences. To generalise about spoken and written English, we need a corpus of spoken and written English (like ICE-GB). To make general statements about US English, we would need a US corpus, and so forth.
- Randomness. In our example, ICECUP locates every case in the corpus that matches form. Hoewever, many cases are found in the same passage. Some cases are found in the same sentence, and even the same noun phrase (as above).
To address this second problem we could select one case from each passage and throw away all other cases. The problem is that this would leave us with a very small number of cases in any typical experiment. The fewer cases in a sample, the less subtle and sensitive the experiment can be.
ICECUP addresses this by estimating the relative independence of each case. It generates an estimate of the likelihood that one case is independent from the other cases in the same sentence. It bases this on the grammatical analysis. The closer that two cases are in the tree structure, the more they are assumed to be co-dependent, thus the two adjacent cases modifying the same noun (above) are assumed to be entirely dependent on one another, with a probability of 0.5 each. Cases at a greater distance are considered to be less affected by each other.
Each case is weighted by this probability score. The analysis uses these scores to weigh up the evidence for and against every hypothesis.
See also experiments: what do we do if cases overlap one another?
This page last modified 7 July, 2020 by Survey Web Administrator.