 Close
Close

UCL and U of T develop software to machine-read medieval Latin texts
28 April 2021
UCL and University of Toronto researchers launch free-to-use AI model for the automated transcription of handwritten Latin manuscripts
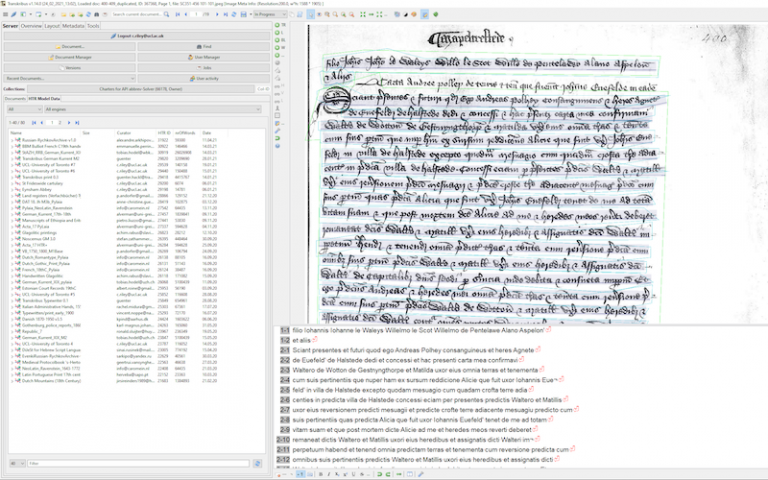
Researchers behind the Bentham Project at UCL and the Documents of Early England Data Set (DEEDS) Project at the University of Toronto (U of T) have collaborated to develop a machine-reading model that uses artificial intelligence to transcribe medieval Latin texts.
The model, which uses the Transkribus platform, was officially launched and made available for free public use at a virtual launch event last month. The joint event was chaired by the project lead, Professor Philip Schofield (UCL Laws), and attended by 180 people.
Following the successful launch, the UCL and U of T teams held a joint virtual training session to demonstrate how to use the new model. The event, training session and collaboration were funded by the UCL-U of T Strategic Partner Funds, which supports joint collaborative projects between the two universities.
Teaming up with researchers at U of T
Before joining forces with the DEEDS team at U of T led by Professor Michael Gervers, Professor Schofield and the Bentham Project were involved in the initial development of the Transkribus software for six years between 2013 and 2019.
The more recent collaboration with U of T focuses specifically on teaching the software to read medieval Latin manuscripts. Over four to five months, the two teams fed the machine, line by line, around 300 pages of handwritten Latin text and the model is now capable of reading over 90 percent of the characters correctly.
Professor Schofield said: “One of the most important breakthroughs was teaching the computer to recognise and expand abbreviations. It was truly a joint effort, with Ariella Elema on the Toronto side providing the accurate transcripts of the Latin material and Chris Riley our side doing layout analysis, which ensures the transcript matches each line of text in an image.”
While the UCL-U of T model has primarily been trained for the automated transcription of 13th-century English charter documents, Professor Schofield’s vision is to eventually combine the machine-reading of manuscripts with crowdsourcing to accelerate the Transcribe Bentham initiative.
Transcribe Bentham was launched in 2010 and engages volunteers to transcribe original correspondence written by Jeremy Bentham over his lifetime (1748-1832). Over 26,000 pages have been transcribed to date.
More information
- Watch: Launch of the UCL/Toronto Transkribus model
- U of T researchers train AI to read difficult-to-decipher medieval texts
- Professor Philip Schofield academic profile
For the latest news about UCL’s international activity, partnerships and opportunities, subscribe to the bimonthly Global Update newsletter.