Improved SI Image Recovery
In the previous installment, we used an
ideal OTF to simulate the use of structured illumination to eliminate out of
focus emissions and get some very crude improvement in lateral resolution. This
time out, we're going to make the process work a little better and try it out on
a slightly more plausible test image.
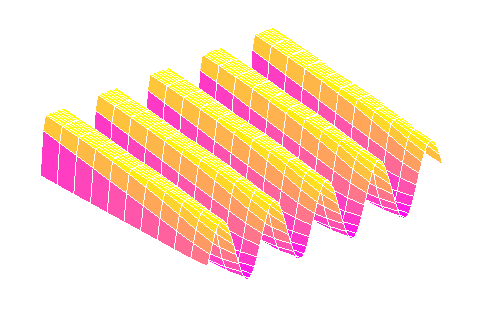
The first thing we're going to do is switch from a sine grating to a rectangular
pulse pattern. There are several reasons for this. For one thing, a rectangular
grating is going to be a lot easier to generate when we start using liquid
crystal componentry, which almost always consists of an array of rectangular
pixels. For another, it allows for better separation between the bright and dark
regions of the focal plane. However, there's a problem.
The sharp edges of a rectangular grating pattern constitute high frequency
components, and won't be faithfully transmitted by the OTF. For cases where the
grating frequency itself is very low compared to the OTF's cutoff, this effect
is more or less negligible -- you're unlikely to notice diffraction blurring
between the stripes of a zebra crossing or the squares on a nearby chessboard.
But as the bands get narrower and narrower, approaching the diffraction limit,
the edges become less and less clear, until the pattern is pretty much
equivalent to a sine grating anyway:








As before, the left is max-min for the full set, right is the verticals and
horizontals processed separately and then added. Both formulæ manage to
recover more dot detail, and generally sharpen things up a bit. But the diagonal
artefacts mentioned before are quite pronounced in the left image -- the
verticals and horizontals are overemphasised at the expense of the other
directions -- and it isn't as successful at separating the dots.
Let's make the OTF more restrictive and see what happens:




Note that we've coarsened the illumination pattern in order to get it through
the OTF. In the conventional (but clean) upper-left image, we're really starting
to lose most of our blobs -- only the biggest can still be clearly
distinguished. And the superiority of the two-stage reconstruction is becoming
obvious: the exaggerated directions are really starting to confound the lower
left image, smearing together blobs that ought to be distinct. By contrast, the
grey blobs in the upper right corner and the white ones in the upper left and
middle of the lower right hand image are most fairly well separated and
countable.
Making things worse still:



And again:




By this point, things have gotten pretty ugly. But still, the two-way composite
is giving us information that just isn't there in the others. No amount of
unsharp mask filtering on the conventional image is going to give us the
separation we're still sneaking out via structured illumination.
Which is pretty cool.
But I have an admission to make.
The optical sectioning mechanism is clear enough. And I understand how the SI
pattern manages to encode higher levels of lateral detail for transport through
the OTF. But I haven't a clue how that detail is being recovered here.
At least, not one I can express with any degree of rigour.
All of the analyses of this business that I've seen require some not necessarily
complicated but at least deliberate manœuvring to pull out the high
frequencies and shift them back to their correct locations in Fourier space.
That is not happening in this case. The image recovery is really simple
arithmetic. There's no specific deconvolution or phase shifting going on. It's
just magic.
Magic is inherently untrustworthy, so at the moment I'm trying, without evident
success, to put this on a firmer footing.
In the meantime, I feel reasonably confident that the whole process will get a
lot more plausibly-ineffectual when I start taking into account noise and
aberrations...
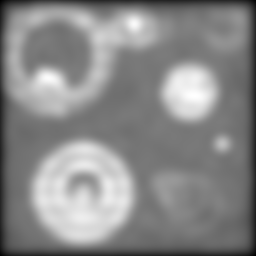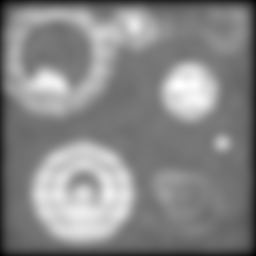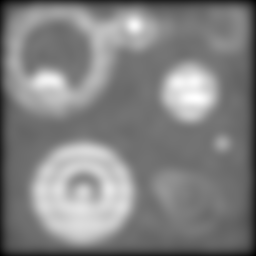
- The bulk of it is black; the 'fluorescent' parts of it are relatively sparse, as we would typically hope to be the case for tagged biological samples.
- There are different levels of intensity (equivalent to fluorophore concentrations).
- There are different levels of detail: big bits and small bits.
- There are objects inside other objects.
- There are curves. Biological entities are rarely rectilinear.