Software for the reMarkable tablet
Table of Contents
| Author | Professor Eric S Fraga (e.fraga@ucl.ac.uk) |
| Last modification | 2022-09-28 08:57:33 |
Introduction
A collection of scripts, mostly, for processing reMarkable tablet documents, both notebooks and annotated PDF documents, on Linux. Use any of these scripts at your own risk; although the author uses these frequently, there is no guarantee that they will work for you.
The mystery (frustration really) for me is that why is it that so many companies use Linux for their products but then provide little or no support for customers that use Linux on their desktop or laptop computers? The scripts here are my attempt to make the best use of the tablet with Linux.
Latest updates
rm2svg.py- incorporated changes from Alan Schmitt which ensure that pages with annotations have the correct geometry (width & height).
Version 41 (2022-09-28T07:58:43Z).
pdf2rm.sh
This script uploads PDF documents to the tablet directly. It creates a set of files that describe a document on the tablet and copies them directly to the xochitl directory on the tablet.
A document on the tablet is represented by a number of individual files and directories in the xochitl directory. These are summarized in this table:
| extension | type | description |
|---|---|---|
| directory | annotations will be stored here | |
| .cache | directory | not sure but empty initially |
| .content | file | information including uuids for each page |
| .highlights | directory | not sure but empty initially |
| .metadata | file | name, dates, type |
| .pagedata | file | list of templates, one per page |
| file | the actual PDF uploaded | |
| .textconversion | directory | for converted annotations; empty initially |
| .thumbnails | directory | 362x512 pixel jpeg, one per page in document |
| numbered 0, 1, …, n-1 |
The script implemented here creates all these files and directories directly in the tablet's xochitl directory with uuids generated using the uuidgen tool on Linux. As there is no description of the actual expected content of some of the data files to be found, I have guessed what the content should be. As a result, this script should be use with care as I am not entirely sure that there are no side effects. My limited testing has not identified any issues but I will take no responsibility for any damage using this script may cause to your tablet!
The script is used as follows:
sshfs root@remarkable.wifi.ip.address:/ ~/remarkable cd <to where your PDF files may be> pdf2rm.sh PDFfile1.pdf [PDFfile2.pdf ...] fusermount -u ~/remarkable
The assumptions are that your reMarkable tablet is on the local network and accessible via ssh and that you have created the suitable mount point (~/remarkable in the example above).
default parameter settings
The REMARKABLE environment variable will be used to determine where to copy the files for the PDF document the user wishes to upload. This scripts assumes that the tablet's full file system (root, aka /) has been mounted at this point.
REMARKABLE=${HOME}/remarkable
get PDF file information
The tablet documents need to know how many pages there are in any PDF document. We use the pdfinfo tool, from the poppler-utils Debian package, to extract this information. The pdfseparate tool from this package will also be used later on to extract the individual pages from the PDF document.
for pdf in $*
do
if [ -f ${pdf} ]; then
n=$(pdfinfo ${pdf} | grep '^Pages' | awk '{print $2}')
name=$(basename ${pdf} .pdf)
date="$(date +%s)000"
echo Uploading PDF document ${name} with ${n} pages, date ${date}
temp=$(mktemp --directory rm.XXXXX)
echo Resulting documents in ${temp}
generate uuid for new tablet document
All files in the xochitl directory of the tablet are based on UUID (universally unique identifier) names. We create one such uuid for this new document and, later, we will also create uuids for each of the pages in the document.
The script also creates a temporary directory on the host system. All the files necessary for the tablet to define a document will be placed here and copied to the tablet at the end of the script. This part of the script prepares the actual PDF document for copying by placing it in the temporary directory with the correct name.
uuid=$(uuidgen)
echo Creating $uuid document directories.
dest=${temp}/${uuid}
mkdir ${dest}
mkdir ${dest}.{cache,highlights,textconversion,thumbnails}
cp ${pdf} ${dest}.pdf
content file
The content file specifies the uuids for each of the pages in the document. We create these uuids here. The values for all the other parameters have been taken from an example document I uploaded using the traditional method (i.e. the Android application, in my case). It could be that some of these parameter values should be different in some cases but I have not yet run into any problems. I would welcome any feedback that says otherwise, of course!
cat > ${dest}.content <<EOF
{
"extraMetadata": {
},
"fileType": "pdf",
"fontName": "",
"lastOpenedPage": 0,
"lineHeight": -1,
"margins": 100,
"orientation": "portrait",
EOF
echo ' "pageCount":' ${n}',' >> ${dest}.content
echo ' "pages": [' >> ${dest}.content
page=1
while [ ${page} -le ${n} ]
do
pageuuid=$(uuidgen)
if [ ${page} -ne ${n} ]
then
echo ' "'${pageuuid}'",' >> ${dest}.content
else
echo ' "'${pageuuid}'"' >> ${dest}.content
fi
((page++))
done
cat >> ${dest}.content <<EOF
],
"textScale": 1,
"transform": {
"m11": 1,
"m12": 0,
"m13": 0,
"m21": 0,
"m22": 1,
"m23": 0,
"m31": 0,
"m32": 0,
"m33": 1
}
}
EOF
metadata file
The important bits of information in this file, as near as I can tell, are the last modification time and the actual name of the document. I am not entirely sure what the other parameters mean except for synced which we specify as false.
cat > ${dest}.metadata <<EOF
{
"deleted": false,
EOF
echo ' "lastModified": "'${date}'",' >> ${dest}.metadata
cat >> ${dest}.metadata <<EOF
"metadatamodified": false,
"modified": false,
"parent": "",
"pinned": false,
"synced": false,
"type": "DocumentType",
"version": 1,
EOF
echo ' "visibleName": "'${name}'"' >> ${dest}.metadata
echo '}' >> ${dest}.metadata
pagedata file
The pagedata file contains one line per page. On each line is the template used. By default, a freshly uploaded PDF document would always (I assume) have a Blank template. It would be interesting to make the template used optional as I can imagine cases where, for instance, a grid template would be good to impose.
page=1
touch ${dest}.pagedata
while [ ${page} -le ${n} ]
do
echo Blank >> ${dest}.pagedata
((page++))
done
thumbnails
Each page in the document has a corresponding thumbnail, a small jpeg image. I do not know if these would be generated automatically by the tablet but it is relatively straightforward to generate these at this point. I have observed that some thumbnails get regenerated on the tablet in any case. Note that the pages are numbered from 0 upwards but the pdfseparate tool used to extract the individual pages numbers from 1. The image creation is done using the convert tool from the ImageMagick (imagemagick-6 to be precise) Debian package.
pdfseparate ${pdf} ${dest}.thumbnails/%d.pdf
page=0
while [ $page -lt $n ]
do
convert ${dest}.thumbnails/$((page+1)).pdf -monochrome -scale 362x512 ${dest}.thumbnails/${page}.jpg
rm ${dest}.thumbnails/$((page+1)).pdf
((page++))
done
copy files to the tablet
At this point, all the necessary files and directories have been created within the ${temp} directory. We now copy these to the tablet. The assumption is that the tablet's file system has been mounted onto this system, probably using sshfs. The location is defined above in the environment variable $REMARKABLE.
( cd ${temp} ; tar cf - . | \
(cd ${REMARKABLE}/home/root/.local/share/remarkable/xochitl/ ; tar xvf - ))
clean up
Remove the temporary files created.
rm -rf ${temp}
end of if and loop for processing each file
fi done
restart xochitl
Once all the files have been created and copied over, we ask the reMarkable tablet to restart the graphical interface, i.e. xochitl. There may be a faster, more efficient way of telling the tablet that there is a new file there but I have not found it yet. Any suggestions would be more than welcome. The script does allow uploading more than one file and only when all have been uploaded is the graphical interface restarted.
This part of the script requires that we log in directly, as root, on the tablet to be able to restart the graphical interface.
ssh root@remarkablewifi systemctl restart xochitl
rmconvert.sh
Convert a remarkable notebook or annotated PDF document to PDF suitable for viewing and/or printing, with colour annotations. This code assumes version 1.7.x of the reMarkable system, the version that introduced the ability to move pages around. The script is here. It relies on an awk script, getpageuuids.awk.
An example of the result for an annotated PDF document:

Usage:
rmconvert.sh UUID
where the UUID argument is the uuid of the document to process, without any extension. The script assumes that the associated files, e.g. uuid.pagedata etc., will be available. For instance, if you have the following files in your current directory,
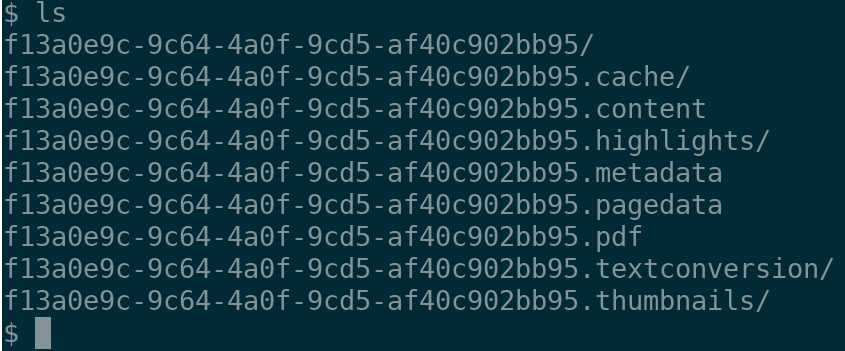
then
rmconvert.sh f13a0e9c-9c64-4a0f-9cd5-af40c902bb95
will decode the .rm files in the f13a0e9c-9c64-4a0f-9cd5-af40c902bb95 directory and use these to overlay the pages found in the f13a0e9c-9c64-4a0f-9cd5-af40c902bb95.pdf document, creating at the end a document /tmp/f13a0e9c-9c64-4a0f-9cd5-af40c902bb95_annotated.pdf.
There are two scenarios: the first is a notebook file which consists solely of what the user has drawn/written using the stylus. The second is where an existing PDF document has been annotated. In either case, we first process the *.rm files which have the drawn/written aspects. Then, if a PDF file exists, these are overlaid on that file.
This script uses a number of other software components:
- rm2svg.py, originally from https://github.com/lschwetlick/maxio/tree/master/tools, used to convert the reMarkable's data recorded when using the stylus to write or draw to an
svggraphic. - inkscape, used to convert the
svggraphic to PDF. - pdfinfo from the
poppler-utilsDebian package, used to determine the orientation and geometry of an existing PDF document that will be overlaid with annotations. - pdftk, used to overlay one PDF on top of another.
- gs from the
ghostscriptDebian package, used to rewrite the final PDF to take up much less space. This is particularly useful (necessary?) when annotating PDF documents created using Microsoft's Word package. As an example, a 277 page document with annotations on approximately 1/3 of the pages led to a final document almost 1 GB in size; after processing viags, the final document was 22 MB in size. The compromise is that the resulting PDF targets display on a screen and hence is at a lower density than would be appropriate for printing in many cases.
All of these, except the first, are standard packages that can be installed on a Debian system easily. The first is available from the author of this script as it has been modified compared with what is available on the 'net.
revision history for rmconvert.sh
List of revisions to the rmconvert.sh shell script:
11. 2020-06-23T16:01:13Z fixed script due to changes in inkscape's arguments for PDF export 10. 2019-06-08T22:43:08Z clean up after finishing the conversion 9. 2019-06-07T23:05:57Z added link for PDF compression web site 8. 2019-06-07T22:50:10Z use gs to compress the PDF pages 7. 2019-06-07T22:34:07Z placed annotated PDF document in /tmp directly 6. 2019-06-07T22:07:09Z annotated document must include non-annotated pages 5. 2019-06-07T21:50:28Z conversion works for notebooks and annotated documents 4. 2019-06-07T21:38:48Z overlaying annotations on PDF document works 3. 2019-06-07T13:23:42Z conversion makes use of templates 2. 2019-06-07T13:12:44Z pages successfully converted to SVG 1. 2019-05-29T10:57:25Z started writing the script
rmlist.sh
List the documents in the xochilt directory of the tablet. The resulting script is here.
getmetadataname
This function extracts the document's name from the metadata file. The argument is the uuid document metadata file.
function getmetadataname {
# echo "Looking for document name in $1"
grep visibleName $1 | sed -e 's/.*": "\?//' -e 's/"\?,*$//'
## grep visibleName $1 | sed -e 's/.*": "//' -e 's/",*$//' -e 's/ /./g'
}
getfullname
Recursively traverse the required uuid files to build up the full name of the document whose uuid has been passed to this function.
function getfullname {
xochitl=${1}
uuid=${2}
meta="${xochitl}/${uuid}.metadata"
documentname=$(getmetadataname ${meta})
# echo Document name is $documentname
# the document may be in a folder. Use the recursive function defined
# above to extra a full path to the destination folder
folders=""
parentuuid=$(grep parent $meta \
| sed -e 's/.*": "\?//' \
-e 's/"\?,*$//' \
-e 's/null,*$// ')
## | sed -e 's/.*": "\?//' -e 's/"\?,*$//' -e 's/ /./g' )
while [[ "$parentuuid" != "" && "$parentuuid" != "null" ]]
do
if [ "$parentuuid" != "trash" ]
then
# echo ".. found folder uuid = $parentuuid"
directoryname=$(getmetadataname ${xochitl}/${parentuuid}.metadata)
# echo ".. with name $documentname"
folders="${directoryname}/${folders}"
# move up a folder
parentuuid=$(grep parent "${xochitl}/${parentuuid}.metadata" \
| sed -e 's/.*": "\?//' \
-e 's/"\?,*$//' \
-e 's/null,*$// ')
## | sed -e 's/.*": "//' -e 's/",*$//' -e 's/ /./g' )
else
folders="trash/${folders}"
parentuuid=""
fi
done
# echo "back in main, folders = $folders"
destination="${destdir}/${folders}"
echo ${destination}${documentname}
}
main block
For each document in the xochitl directory, output the uuid and the full name of the document.
xochitl=${1}
for metadata in $(find ${xochitl} -name '*.metadata')
do
uuid=$(basename ${metadata} .metadata)
# check to see if this is a file or a directory (Collection)
type=$(grep type ${metadata} | sed -e 's/^.*": "//' -e 's/",.*$//' )
# echo 'Checking type of file: ' ${metadata} 'is of type' ${type}
if [ "${type}" == "DocumentType" ]
then
fullname=$(getfullname ${xochitl} ${uuid})
lastchange=$(grep lastModified ${metadata} | sed 's/^.*"\([0-9]\{10\}\).*$/\1/')
date=$(date --date="@${lastchange}" +%Y%m%d-%H:%M:%S)
echo ${uuid} ${date} ${fullname}
fi
done
test
./rmlist.sh ~/xochitl | sort -k 2 -r
Testing code which will be used to create the reMarkable Emacs mode:
(split-string (shell-command-to-string "./rmlist.sh ~/xochitl | sort -k 2 -r") "\n")
reMarkable Emacs mode
introduction
This section implements a major mode for the Emacs system which provides an interface to the documents on the tablet. The mode presents all the documents (both notebooks and PDF) in a human friendly way (I hope) and allows the user to select any to convert to a screen friendly PDF using the rmconvert.sh scripts defined above. The mode depends on the rmlist.sh script defined above and available here.
The inspiration for this mode was this presentation.
The mode is defined in remarkable.el.
The typical usage is:
- copy the
xochitldirectory from the tablet to your local system. I usescpfor this. You can, however, direct the mode to work with the tablet directory if you have mounted the tablet's file system on your own but this is significantlly slower. Customize theremarkable-xochitl-directoryEmacs variable with the actual location on your system. load the Emacs file. This is what I do:
(push "where you downloaded remarkable.el" 'load-path) (require 'remarkable)
invoke the command provided in Emacs:
M-x remarkable RETand the table view of all your documents in thexochitldirectory will be presented: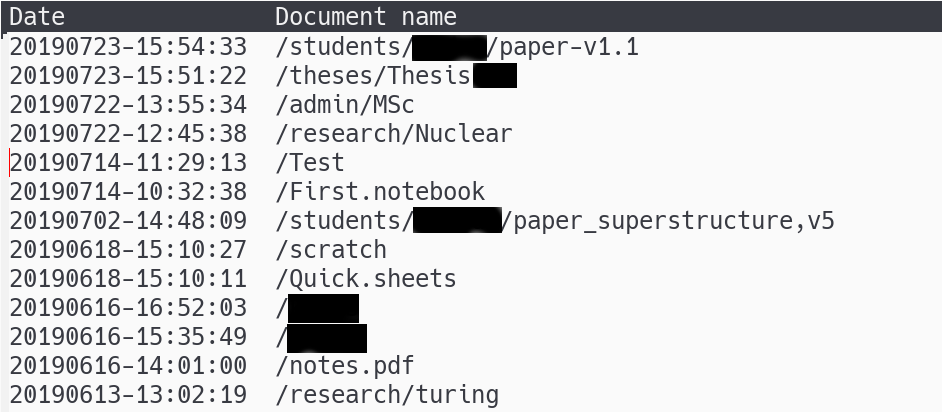
where some entries have been redacted. The entries have been sorted by date with most recent first; the
Skey allows you to sort on either column and in both ascending and descending order.- The
tabulated-list-modeprovides a number of key bindings; type?to see these. Theremarkable-modeadds 2 key bindings to the defaults ones:i- display the
uuidof the entry in the mini-buffer below the window. v- convert, if necessary, the document to PDF and view the PDF within Emacs. This works for both reMarkable notebooks and annotated PDF documents.
custom variables
xochitl directory
The custom variables include the directory where the tablet documents can be found. This could be the tablet's own directory if, for instance, the tablet's file system were mounted on this system, or it may be a copy of such.
(defcustom remarkable-xochitl-directory "~/xochitl" "Directory containing the files from the reMarkable tablet. This should either be a link to the /home/root/.local/share/remarkable/xochitl directory or to a copy of that." :type 'string :group 'reMarkable)
rmlist script
(defcustom remarkable-rmlist-script "~/s/remarkable/software/rmlist.sh" "Where the script for listing the files in the xochitl directory is found." :type 'string :group 'reMarkable)
rmconvert script
(defcustom remarkable-rmconvert-script "~/s/remarkable/software/rmconvert.sh" "Where the script for converting a reMarkable tablet notebook into a PDF file suitable for viewing on the screen. Also used for creating an annotated version of a PDF document." :type 'string :group 'reMarkable)
get the list of documents on the tablet
The argument to the method is the directory where all the files on the tablet are found. In practice, for me, this will be a directory on the local system which has been created by copying all the contents of the /home/root/.local/share/remarkable/xochitl directory from the tablet.
(defun remarkable--get-documents (dir)
(mapcar (lambda (x) (split-string x " "))
(split-string
(shell-command-to-string (concat remarkable-rmlist-script " " dir " | sort -k 2 -r")) "\n")))
convert selected document to PDF and view
(defun remarkable--convert-document-and-view (uuid)
(let* ((uuid (tabulated-list-get-id))
(pdf (concat remarkable-xochitl-directory "/" uuid "_annotated.pdf"))
(tmp (concat "/tmp/" uuid "_annotated.pdf")))
(when (or (not (file-exists-p pdf))
(file-newer-than-file-p
(concat remarkable-xochitl-directory "/" uuid ".content")
pdf))
(message "Converting %s to PDF. Please wait..." uuid)
(shell-command (concat "(cd " remarkable-xochitl-directory "; "
remarkable-rmconvert-script " " uuid "; "
"mv " tmp " " pdf ")"))
(message "... conversion complete.")
)
(find-file pdf)))
define a map for local bindings
(defvar remarkable-mode-map
(let ((map (make-sparse-keymap)))
(define-key map (kbd "i") '(lambda () (interactive) (message "uuid = %s" (tabulated-list-get-id))))
(define-key map (kbd "v") '(lambda () (interactive) (remarkable--convert-document-and-view (tabulated-list-get-id))))
map))
define the derived mode
The mode derives from the tabulated-list-mode which presents a table view into the tablet:
(define-derived-mode remarkable-mode tabulated-list-mode "reMarkable"
"A mode for viewing documents on the reMarkable tablet."
(with-demoted-errors "reMarkable mode error: %s"
(let ((columns [("Date" 18 t) ("Document name" 61 t)])
(rows (mapcar (lambda (x)
(list (car x) (vconcat (cdr x))))
(remarkable--get-documents remarkable-xochitl-directory))))
(setq tabulated-list-format columns)
(setq tabulated-list-entries rows)
(tabulated-list-init-header)
(tabulated-list-print))))
(provide 'remarkable)
define a command to start the mode
Create a buffer (or switch to an existing one) and start up the mode defined above:
(defun remarkable () (interactive) (switch-to-buffer "*reMarkable*") (remarkable-mode) (goto-char (point-min)))
Document revision history
Recent changes to this document:
41. 2022-09-28T07:58:43Z added explicit check for null in parent processing 40. 2022-09-27T07:49:26Z do not replace SPC in file names with "." 39. 2022-09-27T07:46:33Z catch null parentid in metadata 38. 2022-09-27T07:06:24Z fixed the sshfs example instruction 37. 2022-09-23T13:35:56Z trash case handled for documents in sub-folders 36. 2022-09-23T13:33:40Z catch top level deleted documents 35. 2021-07-08T14:05:43Z added latest updates and noted changes to rm2svg.py 34. 2019-09-13T16:20:23Z added direct link to pdf2rm.sh script 33. 2019-09-13T16:18:36Z Comment on the need to have ssh root access to tablet 32. 2019-09-13T16:17:03Z link to local copy of Tao Peng's CSS 31. 2019-09-13T15:29:13Z descriptive text for all the pdf2rm script components written 30. 2019-09-13T08:56:44Z defined REMARKABLE environment variable 29. 2019-09-11T16:31:38Z copy files over to tablet, clean up, and restart xochitl 28. 2019-09-11T14:45:54Z fixed visible name entry 27. 2019-09-11T12:24:26Z all other files created and some minor errors corrected 26. 2019-09-11T11:44:21Z pagedata file created 25. 2019-09-11T11:41:52Z started writing pdf2rm.sh script 24. 2019-08-02T13:56:28Z move point to start when loaded 23. 2019-08-02T12:13:34Z fixed internal link for HTML export 22. 2019-08-02T12:11:12Z very minor change in wording