How FTFs match trees
Simple fuzzy tree fragments (using the ‘Parent’ relation)
So far we have looked at single node FTFs. Thanks to the detail of the ICE grammar - and, in particular, the large number of features - you can do a lot with a single node query in ICE-GB. However, sooner or later you will want to perform a query that involves more than one node. In the first set of examples, we will look at cases where the parent node in the FTF must match the parent node in the tree. We will then look at some more complex examples using the ‘ancestor’ option.
A tightly bound three-node tree fragment
We could start with a two-node (parent and child) fragment, but this is rather limited and anyway, it is similar to the previous ‘tagged word’ example. Instead, we turn to a more obviously treelike example consisting of three nodes.
You can create this FTF in more than one way. One of the simplest is to press ‘New FTF’ to create an empty node with the focus (the one on the left), and then to press 'Insert child after' twice. This inserts two child nodes side-by-side.
Next, move to the first child node and press ‘F2’ or the ‘Edit node’ button. Select “noun phrase head” and “noun” for the function and category respectively. Repeat for the second child node, selecting “clause” for the category. Leave the parent node unspecified.
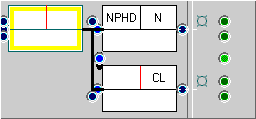
The result should look like the FTF below, left. If you need more help, look at the help manual (included in the complete sample download) under “Editing FTFs”.
This FTF specifies that, thanks to the black arrow (‘Next (child) = immediately after’), the two sibling nodes must follow one another immediately in the sequence (the ‘skip over’ search option may affect this). Secondly, the FTF specifies that the upper node in the FTF that acts as a parent for the other two, is indeed, specified to match only the parent in the tree (in the case below, “[She] she’s a joy to listen to”, the subject complement NP).
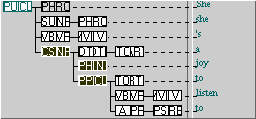
The way that FTFs like this match the corpus is relatively easy to anticipate. If nodes are adjacent and in a particular order in the FTF, they will be adjacent and in that order in the tree. However, sometimes we are interested in weakening these restrictions.
A tree fragment with ‘eventually following’ nodes
Suppose we remove the requirement for the clause to immediately follow the NP head node.
Change the link to ‘after’ (the white arrow) by pressing down with the right mouse button over the blue cool spot in the middle of the arrow.
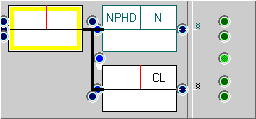
The result should look like the FTF shown here. Performing the search again will find all the previous cases plus some new ones. Thus, in the example shown below (W1A-001 #15, with branches closed for clarity), there are two matches.
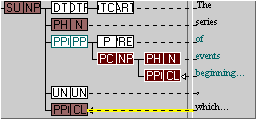
- The matching case on the left, or upper position (i.e., under the subject NP node), contains within it a postmodifying prepositional phrase (“of events beginning...”) followed, eventually, by a (postmodifying) clause.
- The case on the right, within the first, “events beginning in the late fourth century”, also matches the FTF. Here the clause and head nodes are adjacent.
In passing, note that this example illustrates an interesting question regarding sampling that we cannot go into here - can we say that these two cases are entirely independent? See the note below.
A tree fragment with unordered nodes
What if we search for examples but do not specify the order of nodes under the parent (i.e., use a bi-directional arrow)? You may find that it does not appear to make much difference: the grammatical terms you introduce are invariably in a particular order in the tree (or are extremely rare otherwise). If you substitute a ‘before or after’ arrow for the ‘after’ arrow in the previous example and search the sample corpus, there won’t be any additional cases. This is because in the ICE grammar, NP structure is highly ordered.
Not all structures are so regular, and the ability to specify either order can be useful in certain circumstances. However, employing an unordered link can also cause problems. To illustrate this, we will experiment with conjoined NPs.
Create a ‘New FTF’ and add 'two child nodes after' as before. This time, label the first node’s function a “conjoin“ and its category a ”noun phrase” and label the second node with “coordinator“ and “conjunction” respectively. Then, set the linking arrow to ‘just before or after’.
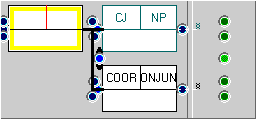
The resulting FTF is given above. Note that when you specify that the link between two nodes is in either order, the two sibling nodes gain additional ‘edge’ options (for the first, ‘Last child’, and the second, ‘First child’). With ordered links (see above), FTFs can dispense with these, because the link guarantees that there must be a node after the first one and vice-versa.
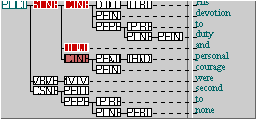
This FTF will find examples of coordinated NP conjoins regardless of order. In the case on the right, it matches twice because there are two NPs and thus two distinct legal matching arrangements.
- The highlighted example (bright red) is in the same ordering arrangement as the FTF.
- The other example is slightly hidden here, due to overlapping, but matches in the other order. It shares the same coordinating node in the middle and the same parent NP node.
If you replace the ‘just before or just after’ (black arrow) with the (white) ‘before or after’ arrow you will get even more combinations, particularly in cases of coordinated triples (“x or y or z”) etc. This kind of FTF may be useful for exploration, but should be avoided for experimentation. You may find that you need to make queries like this more specific in order to perform statistical methods using their results.
A note on statistics and samplingIn this example the two matches overlap one another (unlike the previous example, where they are nested within one another). Apart from the increased difficulty of separating these matches visually - ICECUP lets you distinguish each match by ‘tracking through’ a concordancing display (see help manual) - this also has a number of important implications for the employment of statistics. In brief, statistical methods such as chi-square assume the statistical independence of samples. But it would be hard indeed to argue that the two matches in the example above were independent from one another! Even where two matches are nested within one another you might argue that they are not completely independent. The lesson is: be careful using statistics and examine cases where more than one match is found in the same tree. In particular, avoid treating overlapping cases as statistically independent.
|
On the next page we discuss the use of the ‘ancestor’ relation in trees and reconsider the question of text fragments.
FTF home pages by Sean Wallis
and Gerry
Nelson.
Comments/questions to s.wallis@ucl.ac.uk.
This page last modified 28 January, 2021 by Survey Web Administrator.